CV drives impact in smart manufacturing, healthcare imaging, agriculture, and aerospace (e.g., satellite technology). It often pairs with robotics & autonomous systems for real-time navigation and manipulation; with NLP for OCR and document understanding; and with internet & web technologies to coordinate edge devices in the field.
As a subject of study, CV draws on supervised and unsupervised learning, and increasingly uses reinforcement learning for perception-in-the-loop control. At the frontier, emerging technologies—including quantum computing—hint at new approaches to large-scale visual inference and 3D understanding.

Emerging Applications of Computer Vision
Augmented and Virtual Reality (AR/VR):
Computer vision empowers AR/VR systems to overlay digital content seamlessly onto the user’s view of the real world, enabling immersive experiences in gaming, education, and therapy. For example, AR navigation apps can display turn-by-turn directions on top of live street views. In training and simulation, VR headsets use real-time hand tracking and spatial awareness to let users manipulate virtual controls or explore historical reconstructions. In industrial contexts, technicians using AR glasses can receive live diagrams overlaid on equipment, improving assembly and maintenance precision. Similarly, in healthcare, surgical training platforms simulate operations with responsive visual feedback and holographic patient anatomy.
Advances include markerless motion capture and environment scanning, enabling mobile AR apps to function without pre-defined reference points. Eye-tracking and gesture recognition add natural interaction capabilities, while neural rendering techniques enable fluid transitions between real and virtual elements. This integration facilitates powerful applications like collaborative VR workspaces, immersive storytelling in museums, and remote design prototyping where teams can visualize 3D models in shared virtual spaces.

This stylized image showcases how computer vision powers AR/VR technologies. On the left, a technician uses AR glasses to overlay holographic engine diagrams during machinery maintenance. On the right, a young man with a VR headset and controllers explores a virtual room with a holographic human body and data display, illustrating medical and educational uses.
Retail Analytics:
Smart cameras and shelf sensors backed by computer vision analyze shopper movements, dwell times, and product interactions to extract actionable insights. Retailers can generate visual heatmaps showcasing areas of high foot traffic or delayed purchases, guiding strategic shelf placement, promotional displays, and store layout optimization.
Computer vision-based stock monitoring tracks inventory levels in real time, triggering automatic restocking alerts when shelf space runs low. Smart checkout systems utilize vision to identify items customers place in baskets, reducing the need for scanning. In addition, loss prevention systems identify suspicious behavior—such as concealment or shoplifting—by tracking customer intent and flagging anomalies to security staff.
On the personalization front, CV-powered digital signage adapts to detected demographics—age range, gender, mood—and provides tailored marketing in-store. Integration with loyalty apps allows seamless checkout and personalized discounting triggered by recognized returning customers.
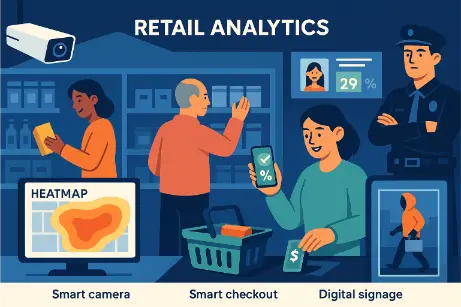
This stylized digital illustration captures the dynamic use of computer vision in modern retail environments. A store interior features smart shelves tracking inventory, overhead heatmap analytics showing customer movement, and a smart checkout counter where a shopper’s items are automatically recognized without scanning. A digital signage panel tailors advertisements based on detected customer demographics, and a staff member monitors a dashboard showing real-time alerts and stock data. The visual communicates how computer vision transforms store operations, personalization, and loss prevention in retail.
Wildlife Conservation:
Camera traps equipped with computer vision effectively identify species, count individuals, and log animal activities automatically in forests, savannas, and marine environments. AI analysis helps researchers monitor population health, track migration routes, and detect poaching events in near-real-time, all without disturbing wildlife.
Drones with multispectral imagers scan large conservation areas, identifying endangered species or mapping habitats. CV algorithms process aerial footage to differentiate between species via distinctive markings or size estimates, enabling automated censuses and habitat usage patterns.
Additionally, computer vision is used in acoustic camera systems that correlate movement with verified sound patterns (like bird calls) for species identification. In marine ecosystems, underwater vision systems detect coral bleaching, fish counts, and pollution impacts—providing continuous environmental monitoring to support timely conservation measures.

This artist impression captures the use of computer vision in wildlife conservation. A tiger, elephant, and bird are tagged in real-time by a drone and smart camera systems, while a conservationist sits in the foreground analyzing live data on a laptop and monitor. The scene showcases how AI assists in species identification, habitat mapping, and real-time population monitoring.
Agriculture:
In precision agriculture, drones and ground robots employ computer vision to scan fields, detecting early signs of plant stress, pest infestations, nutrient deficiencies, or fungal infections. The resulting high-resolution maps enable farmers to target treatments—limiting pesticide and fertilizer use and reducing costs and environmental impact.
Robotic harvesters integrated with vision systems identify and pick ripe fruits or vegetables, adjusting grip and motion to minimize damage and maximize yield. In vineyards, CV detects grape maturity levels and supports automated pruning and thinning, improving harvest timelines and fruit quality.
Soil health monitoring systems combine CV with spectral imaging to assess moisture levels and crop density, guiding seed planting patterns and optimizing irrigation schedules. Vision-based weed detection tools enable autonomous robots to differentiate and remove weeds individually, reducing herbicide use. Post-harvest, computer vision inspects produce for size, shape, or external defects—supporting automated grading and sorting in packing facilities.

This stylized digital artwork depicts an advanced agricultural scene where computer vision technology is integrated into farming operations. A robot equipped with a mechanical arm plucks a ripe tomato while classifying other plants as “weed” or “healthy.” A drone flies overhead collecting data, and a farmer kneels with a laptop showing a crop heatmap. In the background, an autonomous tractor navigates through rows of plants, illustrating a modern, data-driven approach to sustainable farming.
How Computer Vision Works
Technologies Behind Computer Vision
Image Classification:
Image classification is the foundational task in computer vision where a machine assigns a predefined category or label to an entire image. For example, given a photo, the system may determine whether it contains a cat, dog, airplane, or tree. This task is widely used in organizing image databases, recommending content on social media, and enabling AI models to recognize and group similar visuals.
It involves preprocessing images to normalize lighting and scale, followed by feature extraction using convolutional layers in neural networks. State-of-the-art models like ResNet, VGG, and EfficientNet have set benchmarks in classification accuracy by learning hierarchical feature representations. Datasets such as ImageNet have been instrumental in training and testing these models across thousands of object categories.
Beyond static photos, image classification plays a key role in medical diagnostics (e.g., classifying X-rays as healthy or diseased), agriculture (e.g., identifying plant species or diseases), and wildlife monitoring. In educational tools, classification is used to label and sort content based on subject matter or difficulty.
Object Detection:
Object detection advances beyond classification by identifying the presence, type, and precise location of multiple objects within a single image. It generates bounding boxes around detected items and assigns labels, making it essential for applications like autonomous driving, robotics, and surveillance.
Techniques like YOLO (You Only Look Once), SSD (Single Shot Detector), and Faster R-CNN offer varying trade-offs between speed and accuracy. These models scan the image in a grid-like fashion or propose candidate regions, detecting vehicles, humans, animals, or objects of interest in real-time scenarios.
Object detection is used in retail to track customer interactions, in sports analytics to analyze player movement, and in smart cities to monitor traffic flow. Its precision and contextual awareness make it vital in safety-critical systems where understanding spatial arrangements of multiple objects is required.
Semantic Segmentation:
Semantic segmentation refers to labeling each pixel in an image with its corresponding class, thus producing a detailed map of the visual scene. Unlike object detection, which draws boxes, segmentation precisely outlines the shape and extent of objects.
This technique is crucial in applications where boundaries matter—such as medical imaging (e.g., tumor contouring), autonomous driving (e.g., distinguishing road lanes from pedestrians), and satellite imagery (e.g., separating urban areas from vegetation). Tools like U-Net and DeepLab are popular deep learning models for segmentation tasks.
It also supports environmental monitoring by assessing land usage and deforestation and enables smart factories to distinguish between components on assembly lines with pixel-level precision.
Optical Character Recognition (OCR):
OCR enables machines to detect and digitize text from scanned images, documents, signage, and video frames. This technology transforms visual data into machine-readable formats, facilitating automation in administration, translation, and archiving.
Modern OCR systems use computer vision to detect text regions, followed by recurrent neural networks (RNNs) or transformers to decode the character sequences. Tools like Tesseract and Google Vision API have enabled OCR in dozens of languages, including stylized fonts and handwriting.
Applications include automated license plate recognition, passport verification, digitizing handwritten notes in education, and real-time translation apps using smartphones. In legal and financial sectors, OCR helps extract structured data from unstructured scanned documents.
3D Vision:
3D vision allows machines to perceive depth, geometry, and spatial relationships by analyzing 2D images captured from one or more viewpoints. This capability is critical in robotics, virtual reality, and digital twin systems, where understanding the world in three dimensions is essential for interaction and manipulation.
Techniques include stereo vision (comparing two camera views), structure-from-motion (SfM), time-of-flight sensors, and LiDAR. 3D point cloud generation and mesh reconstruction are common outputs that support realistic modeling of objects and environments.
In construction, 3D vision supports building information modeling (BIM) and inspection. In healthcare, it enables volumetric analysis of internal organs using CT or MRI data. In entertainment, it powers motion capture, gaming avatars, and CGI environments.
Foundational Algorithms in Computer Vision:
Edge Detection: Edge detection is a classical technique used to identify boundaries within images. It detects significant transitions in intensity, allowing the identification of shapes, contours, and textures. Common algorithms include the Sobel operator, Prewitt filter, and the Canny edge detector. Canny, in particular, is known for its multi-stage approach—smoothing, gradient calculation, non-maximum suppression, and hysteresis thresholding—yielding clean and thin edges. Edge maps are often used as inputs for higher-level tasks such as segmentation and object recognition.
Simplified Algorithm: Canny Edge Detection
1. Apply Gaussian Blur to reduce noise. 2. Compute intensity gradients using Sobel filters. 3. Apply Non-Maximum Suppression to thin edges. 4. Use Double Thresholding to distinguish strong and weak edges. 5. Track edges using Hysteresis: keep weak edges connected to strong ones.
This algorithm provides a robust framework for extracting meaningful edges and is widely adopted in both classical and modern pipelines.
Feature Detection and Matching: This process extracts distinct points of interest, known as keypoints, from images. Algorithms like SIFT (Scale-Invariant Feature Transform), SURF (Speeded Up Robust Features), and ORB (Oriented FAST and Rotated BRIEF) are used to describe these keypoints with mathematical descriptors, which can then be matched across different images. This enables machines to identify the same object or pattern even under different lighting, scale, or rotation.
Simplified Workflow:
1. Detect keypoints using an interest point detector (e.g., FAST or Difference of Gaussians). 2. Compute descriptors for each keypoint (e.g., BRIEF, SIFT). 3. Match keypoints across images using distance metrics (e.g., Euclidean distance). 4. Refine matches with methods like RANSAC to eliminate outliers.
This workflow underpins applications such as panorama stitching, 3D modeling, and robotic navigation.
Histogram of Oriented Gradients (HOG): A technique that captures edge and gradient orientation patterns, HOG is effective in human detection and object tracking. It represents localized shape features using histograms computed from grid-based cells and blocks.
1. Divide the image into small spatial regions called cells. 2. For each cell, compute the gradient magnitude and orientation for each pixel. 3. Create a histogram of gradient orientations within the cell. 4. Normalize these histograms over larger blocks of cells to account for illumination variations. 5. Concatenate the histograms into a single feature vector representing the image.
HOG features are commonly fed into classifiers such as Support Vector Machines (SVM) for tasks like pedestrian detection in autonomous vehicles or security cameras.
Convolutional Neural Networks (CNNs): The backbone of deep learning in computer vision, CNNs apply layers of filters to learn spatial hierarchies of features. Starting from edges and corners in early layers to abstract object parts in deeper layers, CNNs have dramatically improved accuracy in tasks like classification, detection, and segmentation. Techniques like data augmentation, batch normalization, and transfer learning further enhance CNN performance.
Simplified Workflow:
1. Input image is preprocessed and normalized. 2. Multiple convolutional layers apply filters to extract features. 3. Pooling layers reduce spatial dimensions and computation. 4. Fully connected layers interpret high-level features. 5. Softmax (or sigmoid) layer outputs class probabilities.
CNNs are trained through backpropagation using labeled datasets and are known for their robustness, scalability, and transferability across computer vision tasks.
Image Preprocessing: Techniques such as normalization, histogram equalization, Gaussian filtering, and resizing ensure that input images are consistent in quality and scale before analysis. These steps improve model performance and reduce noise-induced errors.
1. Resize all input images to a consistent size (e.g., 224x224 pixels). 2. Apply Gaussian filter to smooth out high-frequency noise. 3. Perform histogram equalization to enhance contrast. 4. Normalize pixel intensity values to a standard range (e.g., 0 to 1). 5. Optionally apply data augmentation such as flipping, rotation, or cropping.
These steps form the essential foundation for any reliable computer vision model by ensuring uniformity and robustness in input data.
Understanding these theoretical underpinnings equips students and researchers to move beyond using pre-trained models, enabling them to develop novel algorithms and contribute to advancing the state of the art in visual understanding.
Explore World-Class Resources to Learn and Apply Computer Vision
To deepen your understanding of computer vision and its transformative impact, we highlight three authoritative resources that offer high-quality, accessible pathways into the field. The Stanford Car Dataset and Computer Vision Tutorial introduces learners to fundamental concepts and annotated datasets through a structured academic lens. The Computer Vision Foundation connects you to cutting-edge research, real-world applications, and conferences that shape the future of visual intelligence. Meanwhile, PyTorch’s Official Computer Vision Tutorials provide hands-on, beginner-friendly coding environments and pre-trained model zoos, ideal for experimenting with deep learning workflows. Together, these resources form a powerful learning triad—offering theory, discovery, and practice for students, educators, and innovators alike.
Resource 1: Explore Stanford’s Classic Overview of Computer Vision and Its Applications
Stanford University has long been a pioneer in the development and teaching of computer vision, offering foundational resources that have educated generations of students, researchers, and practitioners. Among its most influential contributions is the Stanford Cars Dataset—a meticulously curated benchmark that has become a gold standard in fine-grained image classification and object recognition. The dataset contains over 16,000 images of 196 classes of cars, spanning makes, models, and years. These images are annotated with labels for training and testing, allowing researchers to evaluate how well computer vision models can distinguish subtle differences among visually similar objects.

This digital illustration highlights the essence of the Stanford Cars dataset, showcasing a red sports car, yellow hatchback, and gray sedan rendered in a semi-realistic art style. Positioned against a grid-like background with sketch overlays, the image reflects the diversity of vehicle classes captured in the dataset and the structured approach used for training computer vision models in fine-grained image classification tasks.
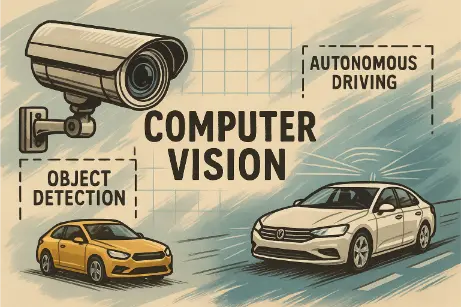
This stylized digital illustration presents key concepts from Stanford’s Computer Vision overview. A surveillance camera and two sedans—one highlighted for object detection and the other representing autonomous driving—are arranged around the bold label “Computer Vision.” Dashed boxes and grid lines visually emphasize these core capabilities, highlighting how computer vision applies to real-world scenarios in security and self-driving vehicles.
Students and professionals benefit from the course’s combination of theoretical lectures, coding assignments, and open datasets. The course walks learners through the intricacies of loss functions, activation layers, optimization methods like stochastic gradient descent, and performance evaluation metrics. The curriculum also introduces cutting-edge techniques such as data augmentation, transfer learning, and the use of pre-trained models, which are essential for building robust computer vision systems today.
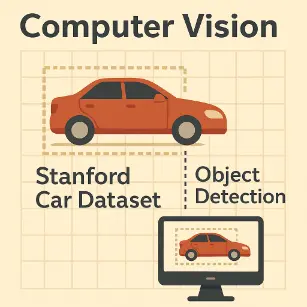
This educational visual presents a simplified flat-style diagram of a red sedan within a dotted bounding box, placed against a beige grid. The image includes text labels—“Computer Vision,” “Stanford Car Dataset,” and “Object Detection”—linked by layout to a monitor showing the same car image. It visually explains the process of object recognition in machine learning using annotated car datasets like Stanford’s.
The Stanford Car Dataset and CV Tutorial together highlight the importance of not just designing accurate models, but also understanding how models interpret nuanced visual cues in high-dimensional data. These resources are routinely referenced in academic papers and serve as the foundation for countless graduate theses and industrial R&D efforts. Moreover, they provide a practical bridge between low-level image processing and high-level AI systems that power autonomous vehicles, intelligent robots, and real-time video analysis.
By exploring Stanford’s classic contributions, learners gain not only access to invaluable tools and datasets but also an appreciation for the evolving challenges in computer vision—ranging from generalization and domain adaptation to fairness and interpretability. Whether preparing for university coursework, contributing to open-source projects, or innovating in industry, these resources equip students with both the technical depth and strategic perspective needed to excel in one of the most dynamic fields in modern AI.
Resource 2: Dive into the Latest Advances and Real-World CV Applications at the Computer Vision Foundation
The Computer Vision Foundation (CVF) is one of the premier global platforms advancing the study and dissemination of cutting-edge research in computer vision. It serves as a hub for academic papers, datasets, and technological demonstrations presented at the world’s top conferences, notably the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), the International Conference on Computer Vision (ICCV), and the European Conference on Computer Vision (ECCV).

This digital artwork captures the essence of cutting-edge research supported by the Computer Vision Foundation. It uses abstract forms and vibrant contrasts—such as a silhouette head with an embedded eye, a desktop screen showing labeled vehicle images, and symbolic representations of AI and neural networks—to evoke the intersection of perception, data, and deep learning. The scene symbolizes how vision algorithms and research shape future technologies in autonomy, analytics, and augmented cognition.
For students, educators, and professionals alike, CVF offers an invaluable resource to explore how the theoretical foundations of deep learning and supervised learning evolve into practical, high-impact applications. Research hosted on the site covers a wide spectrum of topics—from 3D scene reconstruction and semantic segmentation to object detection and human pose estimation—often backed by open-source code and benchmark datasets. This makes it an ideal platform for those pursuing university projects or building prototypes based on recent breakthroughs.
One of CVF’s distinctive strengths is the sheer scale and visibility of its community. Leading labs and companies from around the world submit papers to CVPR and ICCV, ensuring that the content reflects both academic rigor and real-world relevance. For example, recent CVPR proceedings feature developments in autonomous vehicle vision systems, medical image analysis, and even vision-based robotics for agriculture. Each paper not only explains the methodology but often provides experimental results and ablation studies, giving readers an in-depth understanding of how vision algorithms are evaluated and optimized.

This modern digital artwork portrays a computer vision researcher, illustrated with bold lines and vibrant colors, interacting with an on-screen interface that highlights a red car enclosed in a bounding box labeled “CAR.” The background combines geometric circuitry patterns and a dynamic orange-blue contrast, evoking the intersection of AI, engineering, and visual technology. The scene captures a moment of insight and precision, celebrating the role of human expertise in developing intelligent visual recognition systems.
The site also emphasizes transparency and reproducibility—core values in today’s AI research ecosystem. Students accessing CVF materials will find links to GitHub repositories, pretrained model files, and detailed dataset annotations, allowing them to replicate experiments or build upon published work. This facilitates active learning and critical thinking, especially in university courses focusing on robotics, data science, or expert systems.
Educators can use CVF content to supplement lectures with real-world case studies or assign recent papers as reading materials to inspire discussion about ethics, algorithmic fairness, and technological frontiers. Meanwhile, industry practitioners and startup teams consult the CVF library to scout emerging methods that might soon shape autonomous drones, visual inspection tools, or augmented reality interfaces.

A stylized digital illustration depicts a female scientist in a retro-futuristic lab setting, examining visual data from a screen displaying a labeled image of an orange car marked “SAT-CAR.” The screen features bounding boxes and line charts, representing object recognition and data interpretation. In the background, abstract circuit patterns and a futuristic cityscape symbolize the integration of human insight and machine learning. This scene highlights Stanford’s contributions to advancing computer vision through datasets and tutorials.
By diving into the Computer Vision Foundation’s resources, learners not only keep pace with the field’s most recent innovations but also participate in the broader scientific dialogue shaping the future of visual intelligence. Whether exploring foundational topics or aspiring to contribute original research, CVF remains a gateway to excellence in computer vision.
Resource 3: Explore Hands‑On Learning with PyTorch’s Computer Vision Tutorials
The PyTorch Computer Vision Tutorials offer a dynamic and practical entry point for students, educators, and developers seeking to deepen their understanding of visual recognition tasks through modern deep learning techniques. Developed by the creators of the PyTorch framework—one of the most widely adopted platforms for machine learning and AI research—these tutorials bridge foundational concepts with hands-on coding experiences, allowing learners to explore how real-world image classification and object detection models are built, trained, and deployed.

These resources feature step-by-step guidance for tasks such as training neural networks on the CIFAR-10 dataset, implementing transfer learning, using data augmentation to improve model generalization, and deploying models to production-ready pipelines. Learners gain exposure to essential modules such as convolutional neural networks (CNNs), loss functions, optimizers, and GPU acceleration—all in an interactive environment using Python and PyTorch.
A key strength of PyTorch’s educational materials lies in their integration with pre-trained model zoos, which provide ready-to-use architectures like ResNet, AlexNet, and VGG. This allows students to build sophisticated solutions without starting from scratch, fostering faster experimentation and insight. The tutorials also support visualization tools like TensorBoard and Grad-CAM, enabling a clearer understanding of what the model “sees” when interpreting input data.

This modern flat-style digital illustration presents an educational interface for PyTorch’s official computer vision tutorials. It features a computer monitor screen with organized tutorial modules labeled “Neural Networks,” “Datasets,” and “Tensors,” alongside familiar PyTorch syntax like import torch and transform. The image conveys the hands-on and modular nature of PyTorch’s learning environment, aimed at students and developers working on visual AI systems.
For educators and curriculum designers, PyTorch’s modular approach and Jupyter Notebook compatibility make it easy to embed into classroom environments, online courses, or AI bootcamps. Each tutorial is structured to reinforce theoretical knowledge with coding practice, making abstract ideas tangible and testable.
< p> Ultimately, the PyTorch Computer Vision Tutorials stand out not only as instructional materials but as a launchpad for creative innovation. Whether you aim to develop smarter autonomous vehicles, healthcare diagnostics, or intelligent retail systems, these hands-on guides give you the tools to bring your ideas to life.

A flat-design digital illustration shows a young woman enthusiastically coding a convolutional neural network using PyTorch. She sits at a desk with an open notebook, while a diagram on the wall behind her visualizes the Conv-ReLU pipeline in deep learning. This image emphasizes the hands-on, learner-friendly nature of PyTorch’s tutorials and model zoos for mastering computer vision techniques.