Natural Language Processing (NLP) Education can be understood as the disciplined craft of teaching machines to engage meaningfully with human language—while teaching students to understand both the power and the limitations of that craft. The diagram illustrates how raw linguistic material, mathematical foundations, and programming principles enter as inputs. These are shaped by curricular structure, ethical considerations, and research methodologies that act as guiding controls. Through structured learning, experimentation, and model development, students transform these foundations into practical competencies: designing chatbots, building sentiment analysis systems, constructing translation models, and evaluating large language systems responsibly. The mechanisms—software libraries, computational infrastructure, datasets, and expert instruction—form the working engine that enables this transformation. In essence, NLP Education does not merely teach algorithms; it cultivates the ability to bridge language and logic, transforming symbolic human expression into structured computational understanding.
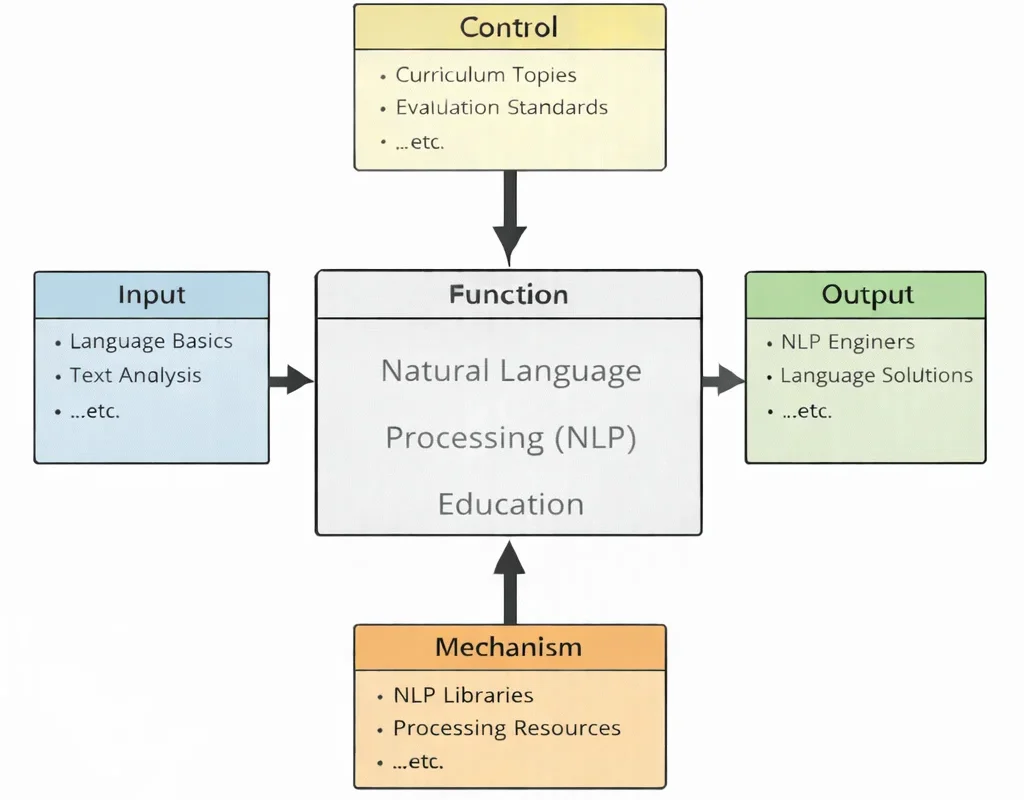
This 1024×1024 IDEF0 diagram presents the structured framework of Natural Language Processing (NLP) Education. At the center is the Function box labeled “Natural Language Processing (NLP) Education,” visually divided by a bold horizontal line beneath the “Function” header band. The left side shows Inputs such as language data, programming foundations, and mathematical concepts flowing into the system. From the top, Controls—including curriculum standards, ethical guidelines, and research frameworks—guide the educational process. On the right, Outputs represent developed competencies such as text analysis skills, model-building capability, and applied NLP solutions. At the bottom, Mechanisms such as computing platforms, software tools, faculty expertise, and learning resources support the function. All elements are presented in a clean, high-contrast, symmetric layout with sharp text and clearly aligned arrows, following standard IDEF0 I–C–O–M conventions.
Natural Language Processing (NLP) teaches computers to read, write, and converse—turning text and speech into structured meaning and useful action. As the medium of human knowledge, language sits at the core of AI; NLP blends ideas from data science & analytics, linguistics, and computer science to make that bridge work in practice. Everyday systems—assistants, chatbots, search, translation, and sentiment analysis—are all powered by NLP.
Modern NLP is driven by deep learning (transformers and large language models) but still relies on classic insights about syntax, semantics, and context. It often pairs with computer vision for multimodal understanding, and with reinforcement learning to align interactive behavior. Rule-driven expert systems still matter in highly structured domains.
Real deployments depend on scalable cloud computing and flexible service models, with inputs flowing through internet & web technologies and, increasingly, IoT/smart devices. In settings like smart manufacturing and robotics & autonomous systems, NLP enables natural interfaces and decision support.
As a subject of study, NLP spans supervised and unsupervised learning, with growing use of reinforcement and instruction tuning for interactive tasks. At the frontier, emerging technologies—including quantum computing—explore new ways to scale inference and optimization for large language models, with downstream impact on communication-heavy domains such as space exploration and satellite technology.
Table of Contents
text classification, named-entity recognition, summarization, translation, information extraction, question answering, and dialogue.
Builds on deep learning with
supervised /
unsupervised learning.
Common evaluation: accuracy & macro-F1 (classification/NER), EM & F1 (QA),
ROUGE (summarization), BLEU / chrF++ or COMET (translation), and perplexity (language modeling).
Key Components of NLP
This section gathers the core building blocks behind modern NLP—spanning text units and structure, meaning and context, model families, data practice, grounding, and production concerns—so learners can move from concepts to working systems.
Text Units & Tokenisation
- Segment text into sentences/tokens; handle morphology and subwords (e.g., BPE/WordPiece).
- Why it matters: defines model inputs; impacts vocabulary, speed, and accuracy.
Normalisation & Pre-processing
- Lowercasing/case-preserve, Unicode normalisation, punctuation rules, stop-word and number policies.
- Clean noisy text (social media, OCR) and decide how to treat emojis, hashtags, code-mixed tokens.
Syntax
- Sentence structure: part-of-speech tagging; constituency & dependency parsing.
- Use cases: grammar checking, information extraction, question answering.
Semantics
- Meaning at word/sentence level: word-sense disambiguation, semantic role labelling, textual entailment.
- Use cases: search relevance, intent understanding, summarisation quality.
Pragmatics & Discourse
- Meaning in context: coreference, discourse relations, idioms/sarcasm, speaker intent, dialogue state.
- Use cases: assistants and chatbots, long-document understanding, safety filters.
Representations
- Embeddings for tokens/sentences: static (e.g., word vectors) vs. contextual (transformer encoders).
- Next step: see Deep Learning for attention/transformers.
Models & Learning
- From classic ML (Naïve Bayes, SVM) to neural models (RNNs, transformers, LLMs).
- Paradigms: supervised, unsupervised, self-supervised pretraining, fine-tuning, parameter-efficient tuning (adapters/LoRA), and prompting.
Prompting, Instruction Tuning & Alignment
- System prompts, few-shot patterns, function/tool calling; instruction-tuned models for helpfulness.
- Reinforcement-style alignment for interactive behaviour (see Reinforcement Learning).
Context Windows, Chunking & Memory
- Long-context strategies: smart chunking, windowed attention, summaries, and cache reuse.
- Trade-offs between latency, cost, and quality for long documents and conversations.
Retrieval & Grounding
- Ground answers in trusted sources with retrieval over documents, databases, or APIs.
- Reduce hallucinations; add citations and provenance for enterprise use.
Data, Evaluation & Responsibility
- Data creation & labelling; splits/QA (see Data Science & Analytics).
- Metrics: accuracy/F1 (classification/NER), EM & F1 (QA), BLEU/COMET/chrF++ (translation), ROUGE (summaries), perplexity (language modelling) plus human review.
- Responsible NLP: privacy, bias, safety policies; document limits and intended use.
Multilingual, Code & Domain Adaptation
- Transfer across languages/scripts; tokenisation issues for morphologically rich languages.
- Adapting models to legal/medical/technical jargon and to code (programming languages).
Speech & Multimodal Interfaces
- ASR/TTS pipelines connect audio to text; OCR links text in images to NLP (see Computer Vision).
- Vision-language models enable captioning, VQA, and grounded dialogue about images/video.
Production Patterns: Inference, Deployment & Monitoring
- Batching, caching, quantisation, streaming, and guardrails; latency vs. quality trade-offs.
- Edge vs. cloud considerations (see Cloud Computing and service models).
- Monitoring drift, feedback loops, and active learning to keep systems current.
Core Tasks in NLP
These are the workhorse problems you’ll meet in real projects. Each card lists what it is, where it’s used, and how to measure it—so you can choose the right approach and know when it’s working.
Text Classification
Assign predefined labels to text (e.g., spam/ham, positive/negative) using supervised learning.- Applications: spam filtering, sentiment, topic tagging, toxicity/moderation.
- Examples: email spam filters; brand sentiment on reviews/social.
Key metrics: Accuracy, Precision/Recall, macro-F1; ROC-AUC / PR-AUC for imbalance. | Starter: sentiment classifier with an error log.
Sequence Labelling (NER, POS, Chunking)
Tag each token with a label (entity types, parts of speech, phrases).- Applications: compliance redaction, resume parsing, clinical notes.
- Examples: detect PERSON/ORG/DATE spans for document pipelines.
Key metrics: token/span F1 (micro/macro); exact-match span rate. | Starter: NER on support tickets with per-entity confusion.
Information Extraction
Pull structured facts from text: entities, relations, and events for analytics or knowledge graphs.- Variants: relation extraction (subject–predicate–object), event extraction (who did what, when).
- Examples: extract drug–adverse-effect pairs from papers; supplier–price from invoices.
Key metrics: span/tuple F1, exact-match on fields; downstream task impact. | Starter: relation extractor over two or three common entity types.
Summarization
Condense documents into concise, factual briefs.- Approaches: extractive (select key sentences) vs. abstractive (paraphrase/compose).
- Examples: news digests; meeting minutes; customer-call briefs.
Key metrics: ROUGE, factuality checks, human preference; for long docs, section-level spot checks. | Starter: 3–5 sentence article summarizer with citation snippets.
Machine Translation
Translate between languages; handle domain and low-resource settings.- Applications: cross-border support, global search, multilingual products.
- Examples: on-device phrase translation; domain-adapted legal/medical MT.
Key metrics: BLEU, chrF++, COMET; targeted human adequacy/fluency reviews. | Starter: few-shot MT with domain phrase glossary.
Question Answering
Return answers from passages (extractive) or generate them (abstractive).- Open-book: retrieve evidence first; closed-book: rely on model knowledge.
- Examples: support FAQs; policy Q&A; academic reading assistants.
Key metrics: EM & F1 (span), faithfulness/citation rate (generative), retrieval Recall@k/MRR. | Starter: PDF Q&A with citations to page anchors.
Dialogue & Conversational AI
Multi-turn assistants with memory, tool use, and guardrails.- Applications: support bots, tutoring, internal copilots.
- Considerations: state tracking, safety, latency, escalation to humans.
Key metrics: task success/containment, first-contact resolution, human preference; safety violations per 1k turns. | Starter: retrieval-augmented FAQ bot with handoff triggers.
Retrieval, Search & RAG
Ground model outputs in your content via lexical + vector search (hybrid).- Pillars: chunking, indexing, re-ranking, citations, and caching.
- Examples: policy copilots; code search; research assistants.
Key metrics: Recall@k, nDCG, MRR; answer faithfulness & citation correctness. | Starter: hybrid search with reranker over your docs.
Document Intelligence (OCR + Layout + NLP)
Understand scanned or complex docs: combine OCR, layout parsing, and field extraction.- Applications: invoices/forms, IDs, contracts, scientific PDFs.
- Bridge: OCR from Computer Vision feeds NLP for fields/relations.
Key metrics: field-level exact match/F1, word-error-rate (OCR), document-level success. | Starter: invoice fields with post-hoc validation rules.
Language Modelling & Generative Text
Predict and generate sequences with transformers (LLMs), optionally instruction-tuned.- Applications: drafting, rewriting, code assistants, creative tools.
- Controls: prompts, system messages, tool calling, style/length constraints.
Key metrics: Perplexity (modeling), human preference, task-specific scores; toxicity/safety rates. | Starter: style-transfer rewriter with before/after diff.
NLP — Data, Evaluation & Deployment
A practical playbook for taking NLP from dataset to dependable product. It covers data practice, task-appropriate metrics, human and retrieval-centric evaluation, and the deployment/monitoring guardrails you’ll actually use.
- Pipeline: collect → clean → label/QA → leakage-safe splits → train/validate/test → monitor & refresh. See Data Science & Analytics.
- Paradigms: supervised/unsupervised + self-supervised pretraining, fine-tuning, parameter-efficient tuning, and prompting (transformers).
- Serving: batch vs real-time on cloud or edge; add guardrails for safety & privacy.
Metrics Cheat-Sheet
| Task | Main metrics | Notes |
|---|---|---|
| Text classification | Accuracy, Precision/Recall, macro-F1, ROC-AUC / PR-AUC | Macro-F1 for imbalance; include confusion matrix & slice metrics. |
| NER / sequence labelling | Token/Span F1 | Report strict span F1; watch boundary errors. |
| Q&A (extractive) | Exact Match, F1 | Slice by question type (who/where/when); check citation correctness for RAG. |
| Summarization | ROUGE, human preference/factuality checks | Spot-check coverage & hallucinations. |
| Machine translation | BLEU, chrF++, COMET | Use domain glossaries; sample for adequacy/fluency. |
| Retrieval / RAG | Recall@k, MRR, nDCG | Also track faithfulness & citation accuracy. |
| Language modelling | Perplexity | Pair with task metrics & safety rates. |
| Calibration & risk | ECE, Brier score | Important when thresholding, abstaining, or triggering tools. |
Tip: always log errors; include per-slice metrics (source, length, language). For safety-critical flows, add violation rate per 1k requests.
Human & safety evaluation
- Human review: small, well-defined rubrics (accuracy, helpfulness, tone), double-rating for agreement.
- Safety: test prompts for PII leaks, bias, and policy violations; track violations per 1k requests.
- Grounding: for RAG, require citations and measure faithfulness to retrieved evidence.
Keep a “canary” set of critical cases to gate releases.
Data practice & splits
- Deduplicate near-identical items; prevent train–test leakage (customer, time, or document-level splits).
- Balance/weight rare classes; augment responsibly; track data lineage and licenses.
- For multilingual or domain data, set per-domain validation slices.
Document dataset cards: provenance, intended use, known limitations.
Retrieval & RAG quality
- Chunking, hybrid search (lexical + vector), re-ranking; cache hot queries.
- Evaluate: Recall@k, nDCG, MRR; answer faithfulness & citation correctness.
- Mitigate hallucinations with strict answer formatting + refusal policies when no evidence.
Deployment & monitoring checklist
- Performance goals: latency/throughput/error budgets; batch/caching; streaming where useful.
- Optimization: quantization, distillation, parameter-efficient adapters; prompt templates versioned.
- Input controls: validation, PII scrubbing, profanity/toxicity filters, file-type and size limits.
- Observability: structured logs, feature stats, prompt/response sampling for review.
- Drift: monitor distribution shift (text length, topic, embedding drift); auto-alerts and retrain triggers.
- Rollouts: shadow mode → canary → A/B; explicit rollback & kill-switch.
- Versioning: pin model + dataset + retrieval index + prompt; record hashes and config.
Privacy, compliance & cost management
- Minimize data retention; redact or hash sensitive fields; region-appropriate storage.
- Access control & key management; audit trails; consent and lawful basis for processing.
- Cost levers: caching, shorter prompts, smaller/quantized models, request batching, response streaming.
Related: refresh Supervised Learning (evaluation basics) and Deep Learning (transformers & fine-tuning).
Additional NLP Applications
Where NLP shows up in products and workflows. Each item links to the relevant concept in this page so readers can go deeper without repetition.
Speech Recognition & Voice Interfaces
Transcribe speech (ASR) and generate responses with TTS for hands-free control and accessibility.
- Examples: voice commands, meeting transcripts, call analytics.
- See: Speech & Multimodal Interfaces
Chatbots & Virtual Assistants
Multi-turn help, ticket triage, tutoring, and internal copilots with memory and tools.
- Examples: website support, HR/IT assistants, study companions.
- See: Dialogue & Conversational AI
Question Answering
Return direct answers from documents or knowledge bases; cite sources when grounded.
- Examples: policy/handbook Q&A, academic reading assistants.
- See: QA & Retrieval/RAG
Opinion & Sentiment Mining
Track sentiment and themes across reviews, social posts, and surveys for brand and product insight.
- Examples: campaign tracking, CX dashboards, market research.
- See: Text Classification
Document Search & Retrieval (RAG)
Find and ground answers with hybrid search (lexical + vector) and re-ranking; add citations.
- Examples: enterprise knowledge portals, code/search copilots.
- See: Retrieval, Search & RAG
Document Intelligence (OCR + Layout)
Turn scans and PDFs into structured data by combining OCR, layout parsing, and field extraction.
- Examples: invoices/forms, ID verification, contract analytics.
- See: Document Intelligence
Technologies Behind NLP
This section focuses on methods and architectures that power NLP systems. For task overviews like NER or sentiment, see Core Tasks in NLP.
Text Representations & Vocabulary
- BoW / TF-IDF: sparse counts; strong baselines for classic classifiers.
- Subword tokenization: BPE, WordPiece, SentencePiece (handles rare/compound words).
- Embeddings: static (Word2Vec, GloVe) vs. contextual (transformer encoders).
Classical ML Models
- Logistic Regression, Linear SVM, Naïve Bayes for classification with BoW/TF-IDF.
- HMMs / CRFs for sequence labelling (e.g., NER, POS) with engineered features.
Neural (Pre-Transformer)
- RNN/LSTM/GRU: model order; seq2seq with attention for MT/summary.
- CNNs for text: n-gram-like filters for fast classification.
Transformers & LLMs
- Self-attention and positional encodings; scalable parallel training.
- Architectures: Encoder (BERT), Decoder (GPT), Encoder–Decoder (T5).
Pretraining Objectives
- Masked LM (BERT-style), Causal LM (GPT-style), Denoising / Seq2Seq (T5-style).
- Contrastive / multitask variants for retrieval and embeddings.
Fine-Tuning & Parameter-Efficient Tuning
- Full fine-tune vs. adapters/LoRA, prefix/prompt tuning (fewer trainable params).
- Great for domain adaptation (legal/medical) and on-prem constraints.
Decoding & Output Control
- Greedy / beam search; top-k & nucleus (top-p) sampling; temperature.
- Constrained generation (schemas, stop words), safety controls, JSON/tool call formats.
Retrieval & Grounded Generation
- Hybrid search (lexical + vector), re-ranking, and caching for RAG.
- Citations/provenance to reduce hallucinations (see Retrieval, Search & RAG).
Tool Use & Function Calling
- Schema-guided outputs to call APIs, DBs, and code; planner–executor patterns.
- Great for assistants that perform actions, not just text replies.
NLP — Starter Projects
Sentiment Classifier
- Goal: classify reviews or posts (positive/negative/neutral).
- Data ideas: small product/movie review sets; your own course/forum exports.
- Baseline → model: TF-IDF + logistic regression → fine-tune a small transformer encoder.
- Evaluate: accuracy, precision/recall, macro-F1; inspect confusion matrix + error log.
- See: Text Classification
- Stretch: handle sarcasm; calibrate probabilities; add topic labels.
Target: macro-F1 ≥ 0.85 on a held-out test set.
News Summariser (3–5 sentences)
- Goal: produce short abstracts for news or blog posts.
- Data ideas: a few dozen–few hundred articles from a school/club site or open news sets.
- Baseline → model: extractive (lead-3 / sentence ranking) → lightweight seq-to-seq.
- Evaluate: ROUGE (1/L) + quick human checklist (factuality, coverage, fluency).
- See: Summarization
- Stretch: length control; headline generation; citation of key sentences.
Target: ROUGE-L ≥ 0.30 on a small, clean test set + zero factual errors in spot checks.
FAQ Bot for a Small Website
- Goal: answer site FAQs via retrieval + generation or extractive spans.
- Data ideas: crawl a handful of pages from your own site; store Q/A in a small JSON/CSV.
- Baseline → model: keyword search + extractive QA → add dense retrieval; optional generative answer with citations.
- Evaluate: Exact Match, F1, and a human helpfulness score (1–5).
- See: Question Answering & Retrieval / RAG
- Stretch: detect out-of-scope queries; add safety filters; caching for popular questions.
Target: EM ≥ 60% on a hidden set; helpfulness ≥ 4/5 in a small user test.
Keyword & Entity Extractor
- Goal: extract keyphrases + named entities to power search facets and analytics.
- Data ideas: news posts, course outlines, or product descriptions.
- Baseline → model: RAKE/TextRank + off-the-shelf NER → fine-tune NER for your domain.
- Evaluate: Span F1 by entity type; precision/recall for keywords.
- See: Sequence Labelling (NER)
- Stretch: relation extraction (who-did-what-to-whom); de-dup & canonicalise entities.
Target: span-F1 ≥ 0.80 overall; ≥ 0.75 for each major entity class.
Document Intake (OCR + Layout + Fields)
- Goal: turn scanned PDFs into structured JSON (invoice/receipt IDs, dates, totals).
- Data ideas: sample receipts/invoices; scanned forms you own consent for.
- Baseline → model: OCR → regex/heuristics → add layout-aware model or fine-tuned field extractor.
- Evaluate: field-level exact-match & span-F1; document-level success rate.
- See: Document Intelligence
- Stretch: confidence thresholds, human-in-the-loop correction, anomaly flags.
Target: ≥ 0.85 EM on required fields; near-zero manual corrections on a small batch.
- Clear goal + metric (e.g., macro-F1, ROUGE-L, EM).
- Data hygiene: train/val/test split; brief data card (source, consent/privacy).
- Baselines vs. improved model with a short comparison table.
- Error analysis: top failure modes (with examples) + what you tried.
- Readme: setup steps, limitations, and responsible-use notes.
- Optional demo: tiny web UI or notebook showing inputs → outputs.
Related refreshers: Supervised Learning, Deep Learning, and Data Science & Analytics.
Natural Language Processing — Learning & Wrap-Up
Challenges in NLP
Ambiguity:
Words and sentences can have multiple meanings depending on the context.
Lack of Context:
Understanding nuanced expressions like sarcasm or idioms can be difficult.
Multilingual Support:
Handling language variations, idiomatic expressions, and grammatical structures across different languages.
Why Study Natural Language Processing (NLP)
Unlocking the Power of Human Language in Computing
Developing Practical Skills in Text Analysis and Language Modeling
Applying NLP to Real-World Challenges
Exploring Ethical and Societal Implications
Opening Doors to Diverse Career Opportunities
Natural Language Processing (NLP): Conclusion
NLP is shifting from model-centric demos to dependable, product-ready systems. Modern workflows blend strong task formulations, high-quality data and evaluation, and pragmatic engineering: retrieval grounding, tool/function calling, long-context handling, and careful deployment with monitoring. Done well, NLP unlocks safer, faster decision-making across healthcare, finance, education, public services, and more.
- Start with the problem, not the model: define inputs/outputs, success metrics, and constraints.
- Make data your moat: leakage-safe splits, dataset cards, and targeted augmentation beat guesswork.
- Measure what matters: use task-appropriate metrics and slice analyses; pair automation with human review.
- Ground and guard: retrieval for citations/faithfulness, input validation, privacy/PII scrubbing, and safety policies.
- Plan for change: monitor drift, log errors, iterate with error analysis, and version models/prompts/indices.
Next steps: pick a project from Starter Projects, review the Data, Evaluation & Deployment checklist, and explore adjacent areas like Deep Learning and Computer Vision for multimodal systems.
NLP: Quick Answers
How much maths do I need? Linear algebra, probability, and some calculus. Start here: Maths for STEM.
What’s a good first NLP project? A small sentiment classifier with a clear macro-F1 goal and an error log.
Which metrics should I report? Classification: Accuracy, Precision/Recall, F1, AUC (imbalance). NER: span F1. Summaries: ROUGE + a quick factuality check. Translation: BLEU/COMET. Language models: Perplexity.
Where do models usually run? Training/serving on cloud computing with pipelines from Data Science & Analytics.
How do I evaluate summaries? Report ROUGE/COMET and add a short human checklist for factuality, coverage, and readability.
NLP Review Questions and Answers:
1. What is natural language processing (NLP) and why is it important in modern IT?
Answer: Natural language processing (NLP) is a subfield of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language. It combines techniques from linguistics, computer science, and machine learning to analyze textual and spoken data. NLP is important in modern IT because it facilitates communication between humans and machines, improves user experience, and automates complex tasks such as translation, sentiment analysis, and content summarization. By transforming unstructured language into actionable insights, NLP drives innovation across various industries including healthcare, finance, and customer service.
2. How do deep learning techniques enhance the performance of NLP systems?
Answer: Deep learning techniques enhance NLP systems by allowing models to learn complex patterns and representations from large volumes of text data automatically. Neural networks, particularly recurrent neural networks (RNNs) and transformers, capture contextual relationships and sequential dependencies that traditional methods often miss. This leads to significant improvements in tasks such as language translation, sentiment analysis, and text generation. The use of deep learning thus enables more accurate, robust, and scalable NLP applications that can process the nuances of human language effectively.
3. What are some common applications of NLP in various industries?
Answer: NLP is applied in a wide range of industries to automate and enhance communication, data analysis, and decision-making processes. In healthcare, it assists in clinical documentation, patient sentiment analysis, and disease diagnosis through analysis of medical records. In finance, NLP is used for fraud detection, market analysis, and customer service automation. Additionally, industries such as retail, education, and legal services benefit from NLP in areas like chatbots, automated content generation, and information retrieval, all of which streamline operations and improve customer engagement.
4. How does sentiment analysis work within NLP, and what benefits does it offer?
Answer: Sentiment analysis in NLP involves processing text to determine the emotional tone or opinion expressed by the author. It typically employs machine learning algorithms and lexicon-based approaches to classify sentiments as positive, negative, or neutral. This technique enables businesses to monitor brand reputation, gauge customer satisfaction, and tailor marketing strategies based on consumer feedback. The benefits include real-time insights, improved customer service, and enhanced decision-making, as organizations can quickly respond to public sentiment and adjust their strategies accordingly.
5. What challenges are associated with processing natural language data in NLP systems?
Answer: Processing natural language data presents several challenges due to the inherent complexity, ambiguity, and variability of human language. NLP systems must handle nuances such as idioms, sarcasm, and context-dependent meanings that can vary widely across different cultures and dialects. Additionally, the vast amount of unstructured text requires robust computational resources and effective preprocessing techniques to extract meaningful insights. Overcoming these challenges demands continuous research, advanced algorithms, and large annotated datasets to improve model accuracy and reliability in real-world applications.
6. How do language models contribute to the development of effective NLP applications?
Answer: Language models are at the core of modern NLP applications, providing statistical and neural network-based frameworks to predict and generate human language. They learn the probability distribution of word sequences and context, enabling them to perform tasks such as text completion, translation, and summarization. By capturing deep linguistic patterns, language models help improve the fluency and coherence of generated text. Their ability to generalize from large datasets makes them invaluable for a variety of applications, driving advancements in communication, content creation, and automated decision-making processes.
7. What role does data preprocessing play in enhancing the performance of NLP systems?
Answer: Data preprocessing is a critical step in NLP that involves cleaning and transforming raw text into a format suitable for analysis by machine learning models. Techniques such as tokenization, stemming, lemmatization, and stopword removal help reduce noise and standardize the input data. Effective preprocessing ensures that the underlying patterns and relationships within the text are preserved and highlighted, leading to improved model training and more accurate predictions. This step lays the foundation for robust NLP systems by ensuring the quality and consistency of the data, which is essential for reliable performance in real-world applications.
8. How do transfer learning and pre-trained models impact the development of NLP applications?
Answer: Transfer learning and pre-trained models have revolutionized the development of NLP applications by allowing developers to leverage knowledge gained from large, diverse datasets. These models, such as BERT, GPT, and ELMo, capture rich linguistic representations that can be fine-tuned for specific tasks with relatively little additional data. This approach significantly reduces training time, improves accuracy, and lowers the resource requirements for developing sophisticated NLP systems. By building on existing models, organizations can rapidly deploy effective solutions in areas such as sentiment analysis, machine translation, and question answering, thereby accelerating innovation and reducing time to market.
9. What advancements in computational power and cloud computing have influenced modern NLP research?
Answer: Modern NLP research has greatly benefited from advancements in computational power, particularly through the use of GPUs and TPUs that accelerate deep learning model training and inference. Cloud computing platforms provide scalable resources that enable researchers to process and analyze massive datasets efficiently. These technological improvements allow for the training of large language models and the execution of complex NLP tasks that were previously impractical on traditional hardware. The synergy between enhanced computational power and cloud infrastructure has democratized access to advanced NLP technologies, driving innovation and enabling real-time applications across various industries.
10. What future trends in NLP are expected to drive innovation in IT and AI, and how might they shape digital communication?
Answer: Future trends in NLP include the continued refinement of large language models, improvements in multilingual processing, and advancements in context-aware and conversational AI. These developments are expected to drive innovation by enabling more natural and effective interactions between humans and machines. As NLP technologies become more sophisticated, they will shape digital communication by facilitating seamless language translation, real-time sentiment analysis, and highly personalized content delivery. The evolution of NLP is poised to transform not only IT and AI but also the broader landscape of digital communication, making interactions more intuitive, efficient, and globally accessible.
NLP Thought-Provoking Questions and Answers
1. How might the evolution of NLP technology transform the future of human-computer interaction?
Answer: The evolution of NLP technology is expected to radically redefine human-computer interaction by enabling systems to understand, interpret, and respond to natural language with greater nuance and accuracy. As NLP models become more advanced, interfaces will shift from command-line inputs to conversational agents that can engage in meaningful dialogues. This transformation will lead to more intuitive and accessible technologies, making it easier for individuals to interact with computers without needing specialized technical knowledge. Enhanced human-computer interaction through NLP has the potential to democratize technology, breaking down barriers and making digital services more inclusive and user-friendly.
Furthermore, this evolution will likely drive the development of adaptive systems that learn from individual interactions and tailor responses accordingly. Such systems could revolutionize customer service, education, and healthcare by providing personalized support and dynamic engagement. The integration of NLP into everyday devices and applications will create a more seamless and natural communication experience, bridging the gap between human intent and machine understanding. As these advancements unfold, the nature of our interactions with technology may become as fluid and intuitive as conversation itself.
2. What ethical considerations arise from the use of NLP in automated decision-making systems?
Answer: The use of NLP in automated decision-making systems brings forth several ethical considerations, particularly concerning bias, transparency, and accountability. NLP models trained on large datasets may inadvertently learn and propagate biases present in the data, leading to unfair or discriminatory outcomes in applications such as hiring, lending, or law enforcement. Ensuring that these systems are transparent and provide understandable explanations for their decisions is crucial to maintaining public trust and accountability. Ethical guidelines and rigorous audits are necessary to mitigate these risks and ensure that automated decisions align with societal values and legal standards.
Moreover, issues of data privacy and consent become critical when NLP systems analyze personal communication and sensitive information. The potential for misuse of such systems, including surveillance or unauthorized data collection, underscores the need for robust regulatory frameworks. Balancing innovation with ethical responsibility requires ongoing collaboration among technologists, ethicists, and policymakers to develop safeguards that protect individual rights while enabling technological progress. The ethical deployment of NLP is essential to ensuring that these powerful tools are used to benefit society without compromising fairness or privacy.
3. How could advancements in NLP contribute to overcoming language barriers globally?
Answer: Advancements in NLP have the potential to significantly reduce language barriers by enabling real-time, accurate translation and cross-lingual communication. With the development of sophisticated multilingual models and translation algorithms, NLP can facilitate seamless interactions between speakers of different languages. This capability not only enhances global communication but also fosters cultural exchange, international collaboration, and access to information across linguistic boundaries. As NLP technology matures, it may lead to the creation of universal translation tools that enable real-time conversations, thereby breaking down long-standing communication obstacles.
Additionally, the integration of NLP with other emerging technologies, such as voice recognition and augmented reality, can create immersive language learning environments. These systems can provide contextualized, interactive experiences that help users learn new languages more effectively. By leveraging large-scale data and continuous learning, NLP-driven translation tools will become increasingly accurate and accessible, contributing to a more interconnected global society. The impact of such advancements could be transformative, enabling individuals and organizations to operate more fluidly in a multilingual world.
4. What role might NLP play in transforming customer service and enhancing user experience?
Answer: NLP is poised to transform customer service by enabling the development of intelligent virtual assistants and chatbots that can handle complex queries and provide personalized support. These systems use natural language understanding to interpret customer needs and generate appropriate responses, significantly reducing wait times and improving service efficiency. By analyzing customer interactions, NLP-driven systems can learn from past conversations to deliver more accurate and relevant assistance over time. This transformation leads to improved customer satisfaction and a more seamless user experience, as users interact with systems that understand and respond in a human-like manner.
Furthermore, NLP can enable proactive customer service by predicting potential issues and offering preemptive solutions. Through sentiment analysis and contextual understanding, these systems can identify customer frustrations and trigger timely interventions, ultimately enhancing the overall customer journey. The integration of NLP into omnichannel support platforms ensures that users receive consistent, high-quality service across various digital touchpoints. As these technologies continue to evolve, the future of customer service will be defined by more personalized, efficient, and engaging interactions driven by advanced NLP capabilities.
5. How can transfer learning in NLP accelerate the development of domain-specific applications?
Answer: Transfer learning in NLP accelerates the development of domain-specific applications by allowing models pre-trained on large, diverse datasets to be fine-tuned on specialized tasks with relatively little additional data. This approach leverages the general linguistic knowledge acquired during pre-training and adapts it to the nuances of a specific domain, such as legal, medical, or technical language. By reducing the need for extensive labeled datasets, transfer learning significantly shortens development time and improves model performance in specialized applications. This strategy is particularly beneficial for organizations with limited resources, enabling them to deploy effective NLP solutions quickly and efficiently.
Moreover, transfer learning enhances the adaptability and generalization of NLP models, allowing them to perform well even when exposed to varied and complex domain-specific data. It facilitates continuous learning and improvement, as models can be updated with new domain data over time to maintain relevance and accuracy. The widespread adoption of transfer learning in NLP is likely to drive innovation across multiple industries by democratizing access to advanced language processing capabilities. This approach not only speeds up the development cycle but also improves the overall quality and reliability of domain-specific applications.
6. How might the convergence of NLP and computer vision lead to breakthroughs in multimedia content analysis?
Answer: The convergence of NLP and computer vision has the potential to create powerful systems capable of analyzing and understanding multimedia content that includes both text and visual elements. By integrating these two technologies, it becomes possible to extract semantic meaning from images, videos, and accompanying textual data, enabling richer and more contextualized insights. This combination can drive advancements in applications such as automated content moderation, video summarization, and cross-modal search, where understanding the interplay between visual and textual information is crucial. The synergy between NLP and computer vision thus opens new avenues for comprehensive multimedia analysis that can enhance user engagement and information retrieval.
Furthermore, this integration supports the development of more sophisticated AI systems that can generate descriptive captions, translate visual content into textual summaries, and even create interactive educational tools. The ability to process and correlate data from multiple modalities will lead to more intuitive and accessible digital experiences, driving innovation in areas such as digital marketing, e-learning, and entertainment. As these technologies continue to converge, the future of multimedia content analysis will be marked by increased accuracy, richer user experiences, and transformative applications that leverage the full spectrum of human communication.
7. What challenges must be overcome to improve the interpretability of deep NLP models, and why is this important?
Answer: Improving the interpretability of deep NLP models is critical to ensuring that their decision-making processes are transparent and understandable to users and stakeholders. One major challenge is the inherent complexity and “black box” nature of deep learning models, which often makes it difficult to trace how specific inputs influence the output. Additionally, the vast number of parameters and layers in these models can obscure the reasoning behind their predictions, leading to issues of trust and accountability. Addressing these challenges requires the development of techniques such as attention visualization, model distillation, and explainable AI frameworks that provide insights into the inner workings of deep NLP models.
Enhancing interpretability is important not only for debugging and improving model performance but also for ensuring ethical and responsible deployment. Clear explanations of model behavior can help detect biases, inform regulatory compliance, and foster greater user trust in AI-driven decisions. As deep NLP models become increasingly integrated into critical applications like healthcare, finance, and legal services, their transparency will be essential for validating their reliability and ensuring that they are used in a fair and accountable manner. Overcoming these challenges is therefore fundamental to the broader adoption and acceptance of advanced NLP technologies.
8. How might advancements in NLP influence the future of education and personalized learning experiences?
Answer: Advancements in NLP have the potential to revolutionize education by enabling personalized, adaptive learning experiences that cater to individual student needs. Through sophisticated language models, educational platforms can analyze student interactions, assess comprehension, and provide customized feedback in real time. This personalization helps students learn at their own pace, addressing specific areas of difficulty and reinforcing strengths, which can lead to improved academic outcomes. NLP-driven tools such as automated tutoring systems, intelligent content recommendation engines, and interactive language learning apps are reshaping how education is delivered, making it more accessible and engaging.
Moreover, NLP can facilitate the integration of diverse multimedia resources into the learning process, enabling seamless interaction between text, audio, and visual content. This creates a more immersive educational environment that adapts to different learning styles and preferences. As these technologies continue to evolve, they will play a pivotal role in transforming traditional educational paradigms, fostering lifelong learning, and empowering students with the skills needed to thrive in a digital world. The long-term impact of NLP on education is expected to be profound, driving innovation and inclusivity across academic and professional landscapes.
9. How can NLP be applied to enhance sentiment analysis and social media monitoring?
Answer: NLP can significantly enhance sentiment analysis and social media monitoring by accurately interpreting the emotions and opinions expressed in vast volumes of user-generated content. By leveraging advanced deep learning models and language processing techniques, NLP systems can analyze text data to determine sentiment polarity, detect sarcasm, and identify trends over time. This enables organizations to monitor public opinion, manage brand reputation, and respond proactively to customer feedback. The high accuracy and scalability of modern NLP approaches allow for real-time analysis, providing actionable insights that drive strategic decision-making in marketing and public relations.
In addition, integrating NLP with data visualization and dashboard tools can further enhance the understanding of sentiment trends and social media dynamics. This integration allows stakeholders to track changes in sentiment across different demographics, regions, or time periods, facilitating targeted interventions and more informed communication strategies. As social media continues to play a central role in shaping public discourse, the ability to harness NLP for sentiment analysis will be crucial for organizations seeking to engage with their audiences and maintain a competitive edge in the digital marketplace.
10. What are the potential impacts of NLP on legal and regulatory processes, particularly in document analysis and compliance?
Answer: NLP has the potential to transform legal and regulatory processes by automating the analysis of complex documents, streamlining compliance, and reducing the workload on legal professionals. Through techniques such as text mining, entity recognition, and semantic analysis, NLP systems can quickly extract relevant information from contracts, legal briefs, and regulatory filings. This automation not only improves efficiency and accuracy but also helps identify potential issues or non-compliance risks early in the review process. By reducing manual effort, NLP empowers legal teams to focus on higher-level strategic tasks and enhances overall regulatory oversight.
Furthermore, the integration of NLP into legal workflows can improve transparency and accessibility by summarizing lengthy documents and highlighting key clauses. These systems can facilitate faster decision-making and support more informed negotiations, ultimately leading to more effective legal processes. As regulatory environments become increasingly complex, the adoption of NLP-driven solutions will be critical in ensuring that organizations remain compliant while managing large volumes of legal data. The future of legal technology is likely to be shaped by these advancements, resulting in more streamlined and responsive regulatory practices.
11. How might interdisciplinary research further advance the capabilities of NLP in creative industries?
Answer: Interdisciplinary research that brings together experts from computer science, linguistics, psychology, and the arts can significantly advance the capabilities of NLP in creative industries. By combining technical innovation with a deep understanding of human language and creativity, researchers can develop NLP systems that generate more nuanced and contextually rich content. These systems can be used to create automated content generation tools, enhance creative writing, and even produce original works of art by understanding and replicating human stylistic nuances. The collaboration across disciplines fosters a holistic approach to problem-solving, ensuring that technological advances in NLP are both technically robust and artistically sensitive.
Moreover, interdisciplinary efforts can lead to the development of new models that capture the subtleties of language in creative contexts, such as metaphors, humor, and cultural references. This synergy can drive innovations in advertising, media production, and entertainment, offering novel ways to engage audiences and tell stories. As a result, the integration of NLP with creative processes not only expands the scope of AI applications but also enriches the artistic landscape, paving the way for transformative experiences in the creative industries.
12. What future innovations in NLP could revolutionize information retrieval and search engine technologies?
Answer: Future innovations in NLP, such as more advanced contextual understanding and semantic search capabilities, could revolutionize information retrieval and search engine technologies by making them far more intuitive and effective. By leveraging deep learning models that capture the full context of queries and documents, search engines can deliver results that are more relevant and personalized to the user’s intent. This progress could lead to significant improvements in query understanding, disambiguation, and the ability to rank results based on nuanced semantic relationships. As a result, users will experience faster, more accurate search results that closely match their information needs, transforming the way we access and interact with information online.
Additionally, these innovations may integrate with other technologies like voice recognition and augmented reality to provide a more immersive search experience. Future search engines could offer interactive, multimodal responses that combine text, images, and video to deliver comprehensive information in real time. Such advancements will not only enhance user satisfaction but also drive further innovation in digital marketing, content creation, and knowledge management. The ongoing evolution of NLP in information retrieval is poised to redefine digital search, making it more intelligent, efficient, and user-centric.
NLP Numerical Problems and Solutions
1. A text corpus contains 5 million words. If an NLP model processes 10,000 words per second, calculate the total processing time in minutes.
Solution:
Step 1: Total processing time in seconds = 5,000,000 / 10,000 = 500 seconds.
Step 2: Convert seconds to minutes = 500 / 60 ≈ 8.33 minutes.
Step 3: Thus, the processing time is approximately 8.33 minutes.
2. An embedding layer has a vocabulary size of 50,000 words with each word represented by a 300-dimensional vector. Calculate the total number of parameters in this layer.
Solution:
Step 1: Total parameters = vocabulary size × embedding dimension = 50,000 × 300.
Step 2: Calculate the multiplication: 50,000 × 300 = 15,000,000.
Step 3: Therefore, the embedding layer has 15 million parameters.
3. A sentiment analysis model achieves 90% accuracy on a dataset of 10,000 reviews. Calculate the number of correct predictions and the number of errors.
Solution:
Step 1: Correct predictions = 10,000 × 0.90 = 9,000 reviews.
Step 2: Errors = 10,000 – 9,000 = 1,000 reviews.
Step 3: Thus, there are 9,000 correct predictions and 1,000 errors.
4. A language model is trained on 2 billion tokens over 50 epochs, with each epoch taking 3 hours. Calculate the total training time in days.
Solution:
Step 1: Total training time in hours = 50 epochs × 3 hours = 150 hours.
Step 2: Convert hours to days = 150 / 24 ≈ 6.25 days.
Step 3: Thus, the total training time is approximately 6.25 days.
5. A machine translation system processes 600 sentences per minute. If there are 100,000 sentences to translate, calculate the total translation time in hours.
Solution:
Step 1: Total time in minutes = 100,000 / 600 ≈ 166.67 minutes.
Step 2: Convert minutes to hours = 166.67 / 60 ≈ 2.78 hours.
Step 3: Therefore, the translation time is approximately 2.78 hours.
6. An NLP preprocessing pipeline takes 0.005 seconds per document. If there are 1,000,000 documents, calculate the total processing time in hours.
Solution:
Step 1: Total time in seconds = 1,000,000 × 0.005 = 5,000 seconds.
Step 2: Convert seconds to hours = 5,000 / 3600 ≈ 1.39 hours.
Step 3: Thus, the total processing time is approximately 1.39 hours.
7. A text classification model has 85% precision and 80% recall on a test set of 5,000 documents, with 3,000 actual positive cases. Estimate the number of true positives if precision and recall hold consistently.
Solution:
Step 1: Using recall: True positives (TP) = 3,000 × 0.80 = 2,400.
Step 2: With precision at 85%, the predicted positives would be TP / 0.85 ≈ 2,400 / 0.85 ≈ 2,823.53.
Step 3: Thus, the model correctly identifies approximately 2,400 true positives.
8. A transformer model has 12 layers and 768 hidden units per layer. If each layer has a self-attention mechanism with a weight matrix of size 768×768, calculate the total number of self-attention parameters for all layers.
Solution:
Step 1: Parameters per layer = 768 × 768 = 589,824.
Step 2: Total parameters for 12 layers = 589,824 × 12 = 7,077,888.
Step 3: Therefore, the total number of self-attention parameters is approximately 7,077,888.
9. A dataset expands from 20,000 sentences to 50,000 sentences after augmentation. Calculate the percentage increase in dataset size.
Solution:
Step 1: Increase = 50,000 – 20,000 = 30,000 sentences.
Step 2: Percentage increase = (30,000 / 20,000) × 100 = 150%.
Step 3: Thus, the dataset size increases by 150%.
10. A speech recognition system processes audio sampled at 16 kHz. Calculate the total number of samples in 1 hour of audio.
Solution:
Step 1: Samples per second = 16,000.
Step 2: Total seconds in 1 hour = 3600 seconds.
Step 3: Total samples = 16,000 × 3600 = 57,600,000 samples.
11. An NLP algorithm reduces feature dimensionality from 10,000 to 1,000 dimensions. Calculate the percentage reduction in dimensionality.
Solution:
Step 1: Reduction = 10,000 – 1,000 = 9,000 dimensions.
Step 2: Percentage reduction = (9,000 / 10,000) × 100 = 90%.
Step 3: Therefore, there is a 90% reduction in feature dimensionality.
12. A batch of text data totaling 500 MB is compressed by an NLP system that achieves a 70% reduction in size. Calculate the size of the compressed data in MB and the compression ratio.
Solution:
Step 1: Compressed size = 500 MB × (1 – 0.70) = 500 MB × 0.30 = 150 MB.
Step 2: Compression ratio = original size / compressed size = 500 / 150 ≈ 3.33.
Step 3: Thus, the compressed data is 150 MB, with a compression ratio of approximately 3.33.
Last updated: