Reinforcement learning education is the study of choice under consequences. Instead of handing a model the “right answers,” RL asks the learner—human and machine alike—to discover strategy through interaction: try, fail, adjust, and try again, until behavior becomes skill. This diagram shows how that discovery is taught without letting it become reckless. The inputs—environment models and reward signals—define the world the agent will live in and the feedback it will receive, shaping what “success” even means. The controls—curriculum topics and safety/ethics criteria—act like a compass and a brake: they structure progress, demand evidence, and remind students that an agent can optimize the wrong thing with alarming efficiency if goals and constraints are careless. Inside the central function, learners practice the real craft of RL: designing state and action spaces, shaping rewards responsibly, managing exploration, diagnosing instability, and separating genuine learning from lucky streaks. The mechanisms—simulators and compute tools—provide the training ground where thousands of trials can occur safely, where experiments can be repeated, and where insights can be earned rather than assumed. The outputs, then, are not just “agents that perform,” but practitioners who understand why they perform—and who can build policies that are effective, testable, and aligned with real objectives in the real world.
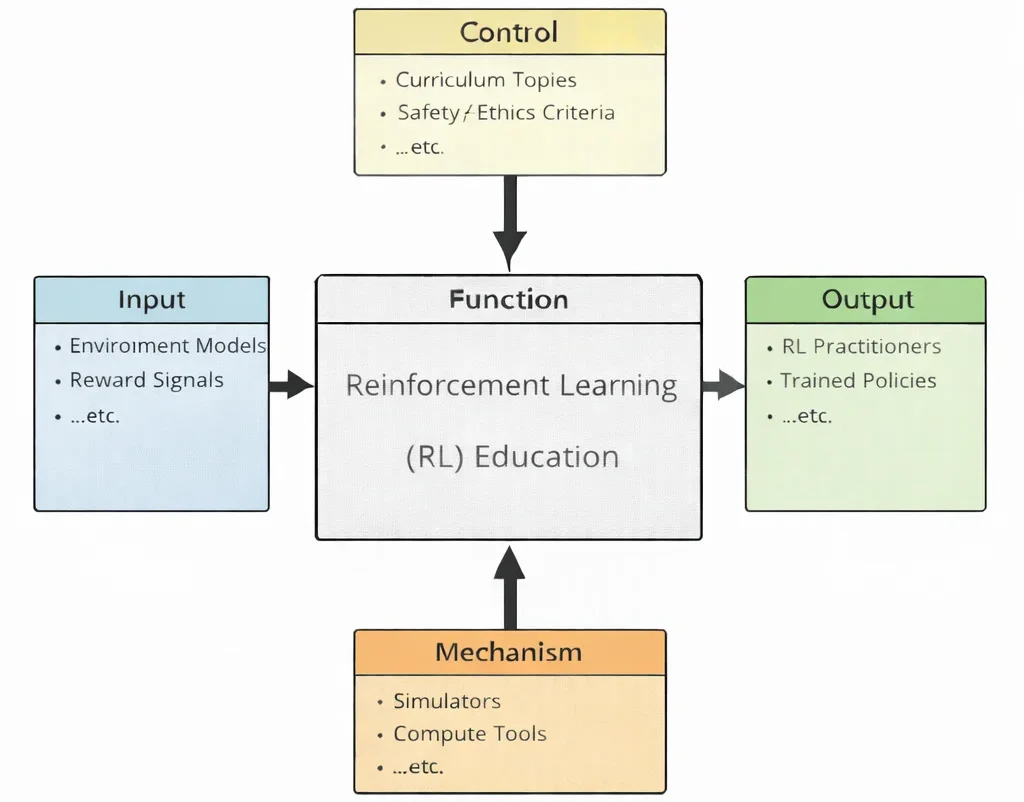
This IDEF0 (Input–Control–Output–Mechanism) diagram summarizes Reinforcement Learning (RL) Education as a structured learning system. Inputs on the left—environment models, reward signals, …etc.—represent the foundations of RL, where learning is driven by interaction, feedback, and sequential decision-making. Controls at the top—curriculum topics, safety/ethics criteria, …etc.—define what is taught and how competence is evaluated, while also imposing constraints that encourage responsible design and experimentation. The central function, Reinforcement Learning (RL) Education, transforms these inputs and controls into applied skill through guided study, experimentation, and iterative improvement of agents and policies. Outputs on the right—RL practitioners, trained policies, …etc.—represent intended outcomes: learners who can design, train, and evaluate RL systems, and learned strategies that perform tasks effectively. Mechanisms at the bottom—simulators, compute tools, …etc.—provide the enabling environment, including simulation platforms and computational resources used to run experiments safely and at scale.
Reinforcement Learning (RL) is a dynamic area within artificial intelligence and machine learning that models learning through interaction and feedback. Unlike approaches in data science and analytics, which extract patterns from static datasets, RL agents discover behaviours by acting in an environment and receiving rewards or penalties. This trial-and-error process enables strong performance in complex decision-making tasks such as game playing, autonomous navigation, and closed-loop control.
RL connects deeply with other AI areas: deep learning provides powerful function approximators; computer vision and natural language processing (NLP) give agents perception and language grounding. At scale, RL systems run on cloud computing with fit-for-purpose cloud deployment models.
In applied settings, RL is pivotal for robotics and autonomous systems, where agents must act safely under uncertainty. In smart manufacturing and Industry 4.0, it drives adaptive control and process optimisation; in IoT and smart technologies, RL closes feedback loops across networks of connected devices.
RL complements—and differs from—other paradigms. In supervised learning models learn from labelled examples; in unsupervised learning they discover structure in unlabelled data. RL instead builds policies from experiential feedback. It also augments expert systems by refining rule-based decisions with adaptive learning.
The relevance of RL is expanding alongside emerging technologies. It already supports space exploration technologies and satellite technology, and may ultimately benefit from advances in quantum computing (e.g., qubits, superposition, quantum gates).
Rooted in STEM and enriched by information technology, RL equips students to work at the frontier of intelligent decision-making—whether optimising supply chains, training self-driving vehicles, or supporting autonomy in critical systems.

Table of Contents
Core Principles of Reinforcement Learning
Agents, Actions, and States:
- Agent: The decision-making entity, such as a software program controlling a virtual character, or a physical robot navigating a room.
- States: The agent observes the state of the environment at each step. A state may include the agent’s position, objects it interacts with, or other relevant features.
- Actions: At any given state, the agent chooses an action from a set of possible actions. The outcome of that action changes the environment’s state and affects future decisions.
Rewards and Penalties:
The environment provides feedback in the form of a numerical reward (which can be positive or negative). When the agent performs an action that advances its goals, it receives a positive reward; if it takes a counterproductive action, it might receive a penalty or a lower reward. Over time, the agent learns to associate certain actions in certain states with higher cumulative rewards.
Goal of Maximizing Cumulative Reward:
The objective in reinforcement learning is not just to achieve an immediate reward but to maximize the sum of rewards over the long run. This focus on cumulative gain encourages the agent to develop strategies that balance short-term gains against long-term benefits. For instance, the agent might delay immediate gratification to secure more substantial rewards later.
Exploration vs. Exploitation:
A key challenge in RL is the trade-off between exploration—trying new actions to discover potentially better rewards—and exploitation—using known strategies that have previously yielded good results. Finding an appropriate balance allows the agent to continually improve without getting stuck in suboptimal patterns of behavior.
Fundamental Techniques and Algorithms
This page covers the main families of RL methods. Use the quick map below to jump into the detailed sections you’ve added.
- Learn action-values \(Q(s,a)\); act greedily from the value estimates.
- Great for discrete actions and tabular or pixel tasks with replay buffers.
- Directly optimise a stochastic policy \(\pi_\theta(a\mid s)\); handles continuous actions naturally.
- Use baselines/advantages to reduce variance; PPO adds clipping for stable updates.
- Actor chooses actions; critic estimates value/advantage for low-variance updates.
- SAC adds entropy regularisation and a learned temperature for smooth continuous control.
- Model-Free RL: learn policy/values directly from experience (simpler, robust; more data-hungry).
- Model-Based RL: learn dynamics/reward models to plan or imagine data (more sample-efficient; needs model care).
Tip: If visitors only need a primer, keep this overview. For advanced readers, your deep sections (exploration, shaping/curriculum, model-based, diagnostics) provide the full playbook.
Mathematical Foundations: MDPs & Bellman Equations
Markov Decision Processes (MDPs)
We model RL tasks as an MDP \( \mathcal{M} = \langle \mathcal{S}, \mathcal{A}, P, R, \gamma \rangle \), with states \( \mathcal{S} \), actions \( \mathcal{A} \), dynamics \( P(s' \mid s,a) \), reward \( R(s,a) \), and discount \( \gamma \in [0,1) \). Problems may be episodic (terminal state) or continuing.
Returns, Policies, and Value Functions
- Return (discounted future reward): \( G_t = \sum_{k=0}^{\infty} \gamma^{k} \, r_{t+k+1} \).
- Policy: stochastic \( \pi(a \mid s) \) or deterministic \( \mu(s) \).
- State value: \( V^{\pi}(s) = \mathbb{E}_{\pi}[ G_t \mid S_t = s ] \).
- Action value: \( Q^{\pi}(s,a) = \mathbb{E}_{\pi}[ G_t \mid S_t = s, A_t = a ] \).
- Advantage: \( A^{\pi}(s,a) = Q^{\pi}(s,a) - V^{\pi}(s) \).
Bellman Equations
Expectation (under a fixed policy)
\[ V^{\pi}(s) = \sum_{a} \pi(a \mid s) \Big[ R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) \, V^{\pi}(s') \Big] \] \[ Q^{\pi}(s,a) = R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) \sum_{a'} \pi(a' \mid s') \, Q^{\pi}(s',a') \]
Optimality (replace the policy expectation with a max)
\[ V^{*}(s) = \max_{a}\Big[ R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) \, V^{*}(s') \Big] \] \[ Q^{*}(s,a) = R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) \, \max_{a'} Q^{*}(s',a') \]
Dynamic Programming (tabular, model known)
- Policy Evaluation: iteratively apply the Bellman expectation operator to get \( V^{\pi} \).
- Policy Improvement: update policy greedily w.r.t. current values (e.g., \( \pi_{\text{new}}(s) = \arg\max_{a} Q^{\pi}(s,a) \)).
- Policy Iteration: alternate evaluation & improvement until stable.
- Value Iteration: one-step lookahead with the optimality operator; converges to \( V^{*} \).
Temporal-Difference Learning (sample-based, model-free)
TD(0) state-value update
\[ V(S_t) \leftarrow V(S_t) + \alpha \big[\, r_{t+1} + \gamma V(S_{t+1}) - V(S_t) \,\big] \]
Q-learning (off-policy control)
\[ Q(S_t,A_t) \leftarrow Q(S_t,A_t) + \alpha \big[\, r_{t+1} + \gamma \max_{a'} Q(S_{t+1},a') - Q(S_t,A_t) \,\big] \]
SARSA (on-policy control)
\[ Q(S_t,A_t) \leftarrow Q(S_t,A_t) + \alpha \big[\, r_{t+1} + \gamma Q(S_{t+1},A_{t+1}) - Q(S_t,A_t) \,\big] \]
Practical notes
- Effective horizon \( \approx \tfrac{1}{1-\gamma} \); choose \( \gamma \) to match task length.
- Use reward shaping cautiously. Potential-based shaping preserves optimality: add \( F(s,s') = \gamma \Phi(s') - \Phi(s) \) for some potential \( \Phi \).
- Normalize returns; watch for bootstrapping instability and step-size \( \alpha \).
- Separate exploration (e.g., \( \epsilon \)-greedy) from evaluation (greedy).
Policy Gradients & Actor–Critic (with PPO/GAE)
Value-based methods (e.g., Q-learning) search for a good policy indirectly by first learning values and then acting greedily. Policy-gradient methods go straight for the goal: they adjust a parameterised policy \( \pi_\theta(a \mid s) \) to maximise the expected return. This is attractive for large or continuous action spaces and for policies that must remain stochastic (to keep exploring or to model mixed behaviours).
Objective and the “log-trick”
Define the performance objective \[ J(\theta) \;=\; \mathbb{E}_{\tau \sim \pi_\theta} \Big[ \sum_{t=0}^{T-1} \gamma^t r_{t+1} \Big], \] where a trajectory \( \tau \) is sampled by running \( \pi_\theta \). Using the log-derivative identity \( \nabla_\theta p(x) = p(x)\,\nabla_\theta \log p(x) \), the policy-gradient theorem gives \[ \nabla_\theta J(\theta) \;=\; \mathbb{E}_{\pi_\theta}\!\Bigg[ \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(A_t \mid S_t) \; G_t \Bigg], \] with return \( G_t = \sum_{k=t}^{T-1} \gamma^{k-t} r_{k+1} \). Intuition: increase the probability of actions that led to higher return; decrease it for actions that did poorly.
Variance reduction: baselines and advantages
Directly using \( G_t \) is unbiased but noisy. We can subtract any baseline \( b(S_t) \) without changing the expectation (because \( \mathbb{E}[\nabla_\theta \log \pi_\theta \, b(S_t)]=0 \)): \[ \nabla_\theta J(\theta) \;=\; \mathbb{E}_{\pi_\theta}\!\Bigg[ \sum_{t} \nabla_\theta \log \pi_\theta(A_t \mid S_t) \; \big( G_t - b(S_t) \big) \Bigg]. \] The best practical baseline is the value function \( V^\pi(S_t) \), producing the advantage \( A^\pi(S_t,A_t) = G_t - V^\pi(S_t) \): “how much better was this action than we expected?”
REINFORCE (Monte-Carlo policy gradient)
- Collect full episodes with the current policy \( \pi_\theta \).
- Compute returns \( G_t \) (or advantages \( G_t - b(S_t) \)).
- Update: \[ \theta \leftarrow \theta + \alpha \sum_{t} \nabla_\theta \log \pi_\theta(A_t \mid S_t) \; (G_t - b(S_t)). \]
Pros: simple, unbiased. Cons: high variance; slow learning. That’s why most practical agents add a critic to supply a strong baseline and use bootstrapping.
Actor–Critic: learn a policy and a value function together
We parameterise a policy \( \pi_\theta \) (the actor) and a value function \( V_w \) (the critic). At each step we form a TD error \[ \delta_t \;=\; r_{t+1} \;+\; \gamma \, V_w(S_{t+1}) \;-\; V_w(S_t), \] which is a low-variance estimate of the advantage.
- Critic update (regression to a TD target): \[ w \;\leftarrow\; w \;-\; \alpha_v \, \nabla_w \big( V_w(S_t) - (r_{t+1} + \gamma V_w(S_{t+1})) \big)^2. \]
- Actor update (policy gradient with advantage): \[ \theta \;\leftarrow\; \theta \;+\; \alpha_\pi \, \nabla_\theta \log \pi_\theta(A_t \mid S_t)\; \hat A_t, \] where \( \hat A_t \) is \( \delta_t \) or a multi-step/GAE estimate.
Generalized Advantage Estimation (GAE)
GAE trades bias for variance using a smoothing parameter \( \lambda \in [0,1] \). First define TD residuals \( \delta_t = r_{t+1} + \gamma V_w(S_{t+1}) - V_w(S_t) \). Then accumulate \[ \hat A_t \;=\; \sum_{l=0}^{\infty} (\gamma \lambda)^l \, \delta_{t+l}. \] Rule of thumb: \( \lambda \approx 0.95 \) often works well; lower \( \lambda \) reduces variance but can increase bias.
PPO: stable actor–critic updates
Proximal Policy Optimisation limits how much each update can change the policy by using a clipped objective. Let \( r_t(\theta) = \frac{\pi_\theta(A_t \mid S_t)}{\pi_{\theta_{\text{old}}}(A_t \mid S_t)} \) be the probability ratio.
Clipped surrogate objective: \[ L^{\text{clip}}(\theta) \;=\; \mathbb{E}\Big[ \min\big( r_t(\theta)\,\hat A_t,\; \mathrm{clip}(r_t(\theta),\, 1-\epsilon,\, 1+\epsilon)\,\hat A_t \big) \Big]. \] The total loss typically combines actor, critic, and entropy: \[ \mathcal{L}(\theta, w) \;=\; -L^{\text{clip}}(\theta) \;+\; c_v \, \mathbb{E}\big[ (V_w(S_t) - \hat V_t)^2 \big] \;-\; c_e \, \mathbb{E}\big[ \mathcal{H}(\pi_\theta(\cdot \mid S_t)) \big]. \] Here, \( \hat V_t = V_w(S_t) + \hat A_t \) or a multi-step return; \( \mathcal{H} \) is entropy to keep the policy exploratory; \( \epsilon \in [0.1, 0.3] \) is common.
Putting it all together (plain-English training loop)
- Run the current policy for \(N\) steps across \(M\) environments; store \( (S_t, A_t, r_{t+1}, S_{t+1}, \log \pi_{\theta_{\text{old}}}(A_t \mid S_t)) \).
- Compute \( V_w(S_t) \) and advantages \( \hat A_t \) (e.g., GAE). Normalise \( \hat A_t \) to zero-mean/unit-std.
- For several epochs, shuffle the data and update:
- Actor: maximise \( L^{\text{clip}}(\theta) \) (or minimise its negative).
- Critic: minimise the value loss \( \|V_w - \hat V\|^2 \).
- Entropy bonus: encourage sufficient exploration early on.
- Set \( \theta_{\text{old}} \leftarrow \theta \) and repeat.
When to use what?
- REINFORCE: conceptually simplest; works for small problems and as a teaching baseline.
- Actor–Critic (A2C/A3C): faster learning with TD advantages; good default for many tasks.
- PPO (with GAE): robust, widely used for continuous control (robotics, locomotion) and many discrete tasks.
Practical tips (that save days of debugging)
- Normalise advantages per update batch; it stabilises the actor step.
- Clip policy updates (PPO) and clip value targets if needed to avoid exploding losses.
- Entropy schedule: start higher to explore; decay as learning progresses.
- Continuous actions: model \( \pi_\theta \) as a factorised Gaussian; learn mean and (log) std; squash by \(\tanh\) if actions are bounded and correct the log-prob.
- Rewards: scale/normalise; consider reward shaping via potential functions \( F(s,s')=\gamma\Phi(s')-\Phi(s) \) to keep optimality intact.
- Diagnostics: track explained variance of the critic, KL vs. clip range, advantage stats, value loss, and episode returns. If KL spikes or the clip fraction is near 0/1, tune learning rate or \( \epsilon \).
Exploration Strategies & Intrinsic Motivation
Reinforcement learning agents must discover high-reward behaviours. Good exploration balances trying new actions with exploiting what already works. Below we move from classic bandit ideas to modern entropy-regularised and curiosity-driven methods, with plain-English guidance and the key equations.
1) Bandit & Tabular Foundations
- \(\varepsilon\)-greedy: with probability \( \varepsilon \) choose a random action; otherwise take \( \arg\max_a Q(s,a) \). Anneal \( \varepsilon \) from \(0.2\!\sim\!0.5\) to \(0.01\!\sim\!0.05\).
- Boltzmann / Softmax: \[ \pi(a\mid s) \;=\; \frac{\exp\big(Q(s,a)/\tau\big)}{\sum_{a'} \exp\big(Q(s,a')/\tau\big)}, \] where temperature \( \tau\!\downarrow \) makes the policy greedier.
- Upper Confidence Bound (UCB) for bandits: \[ a_t \;=\; \arg\max_a \Big[\; \hat Q(a)\;+\; c\,\sqrt{\frac{\ln t}{n(a)}} \;\Big], \] optimism via the bonus shrinks as arm count \( n(a) \) grows.
- Optimistic initial values: set \( Q_0 \) high so early actions look promising (forces early trials).
2) Entropy-Regularised RL (PPO entropy bonus, SAC temperature)
Add an entropy term to prefer stochastic policies and avoid premature collapse. For state \(S_t\) and policy \(\pi\), the discounted objective with temperature \(\alpha>0\) is
\[ J_\alpha(\pi) \;=\; \mathbb{E}\!\left[\sum_{t=0}^{T-1} \gamma^t\,\big(r_{t+1} + \alpha\,\mathcal H(\pi(\cdot\!\mid\!S_t))\big)\right], \qquad \mathcal H(\pi(\cdot\!\mid\!s)) = - \sum_a \pi(a\!\mid\!s)\,\log \pi(a\!\mid\!s). \]
- PPO: add an entropy bonus \(-c_e\,\mathcal H\) to the total loss to keep exploration early.
- SAC (Soft Actor–Critic) formalises this with soft values: \[ V(s) \;=\; \mathbb{E}_{a\sim\pi}\big[\, Q(s,a) - \alpha \log \pi(a\mid s) \,\big]. \] Policy update minimises the KL to the Boltzmann distribution \( \propto \exp(Q/\alpha) \). Temperature can be learnt by minimising \[ \mathcal L(\alpha) \;=\; \mathbb{E}_{a\sim\pi}\!\left[ -\,\alpha\,\big(\log \pi(a\mid s)+\mathcal H_{\text{target}}\big) \right], \] driving the policy to a target entropy (e.g., \(-\)action-dim).
3) Intrinsic Motivation (Novelty & Curiosity Bonuses)
For sparse or deceptive tasks, give the agent an internal reward for novelty or learning progress. Combine external and intrinsic rewards as \[ r^{\text{total}}_t \;=\; r^{\text{ext}}_t \;+\; \beta\, r^{\text{int}}_t , \] where the scale \( \beta \) is crucial (start small, e.g., \(10^{-3}\!\sim\!10^{-1}\), and tune).
3.1 Count-Based Exploration
In tabular settings a simple bonus works well: \[ r^{\text{int}}(s) \;=\; \frac{\beta}{\sqrt{N(s)}} , \] where \( N(s) \) is the visit count. For large spaces, use pseudo-counts via a density model \(\rho_\theta(x)\). If \(\rho_t(x)\) is the probability before seeing \(x\) and \(\rho_t'(x)\) after a one-step update on \(x\), a common pseudo-count is \[ \hat N(x) \;=\; \frac{\rho_t(x)\,\big(1-\rho_t'(x)\big)}{\rho_t'(x)-\rho_t(x)},\qquad r^{\text{int}}(x) \;=\; \frac{\beta}{\sqrt{\hat N(x)+\epsilon}} . \]
3.2 Curiosity via ICM (Inverse & Forward Models)
Map states to features \( \phi(s) \). Train:
- Inverse model \( g \): predict \( a_t \) from \( (\phi(s_t),\phi(s_{t+1})) \) (helps learn action-aware features).
- Forward model \( f \): predict next features from state and action.
Intrinsic reward is the forward prediction error—surprise in feature space: \[ r^{\text{int}}_t \;=\; \eta\,\big\|\, \phi(s_{t+1}) \;-\; f\big(\phi(s_t),a_t\big) \,\big\|_2^2 . \] Use a small \( \eta \) and normalise this bonus online (running mean/std) to keep scales stable.
3.3 Random Network Distillation (RND)
Keep a fixed, randomly initialised target network \( f_{\text{t}}(s) \). Train a predictor \( f_{\text{p}}(s) \) to match it. Novel states are harder to predict, giving a larger error: \[ r^{\text{int}}_t \;=\; \eta\,\big\|\, f_{\text{p}}(s_t) - f_{\text{t}}(s_t) \,\big\|_2^2 . \] This works well in hard-exploration games; remember to normalise and to stop the predictor from overfitting the replay distribution (e.g., use large/refreshing buffers and layer norm).
Implementation notes & pitfalls (high-leverage tips)
- Always log returns separately: track extrinsic, intrinsic, and total. Evaluate policies with intrinsic reward off to measure real task progress.
- Normalise bonuses (running mean/std) and clip to a sane range before mixing with \( r^{\text{ext}} \).
- Scale & schedule \(\beta\): start larger to drive exploration, then decay once dense rewards take over.
- Continuous control: keep Gaussian policy std above a floor; in PPO, don’t anneal entropy too quickly.
- NoisyNets / parameter noise: sample weights \( w = \mu + \sigma \odot \varepsilon \) so the policy changes coherently across states (often better than action-space noise).
- Bootstrapped heads (DQN) approximate Thompson sampling; each head trains on its own bootstrap of data.
- Reward hacking: curiosity can dominate; monitor “stuck but curious” behaviours (e.g., jitter in novel corners).
4) Safe Exploration with Constraints (Lagrangian)
If there is a per-step cost \( c_t \) (collisions, rule violations), enforce a long-run limit \( J_C(\pi)\!\le\!d \) using a Lagrange multiplier \( \lambda\ge 0 \):
\[ \max_\pi \;\; J(\pi) - \lambda\big( J_C(\pi)-d \big). \] Update policy parameters to increase the penalised objective, and update \[ \lambda \;\leftarrow\; \big[\, \lambda + \eta_\lambda\,\big(J_C(\pi)-d\big) \,\big]_+ . \] In practice: shape rewards as \( r^{\text{safe}}_t = r^{\text{ext}}_t - \lambda\, c_t \), and learn \(\lambda\) online.
5) Practical Recipes (What to try first)
- PPO + entropy bonus (clip \( \epsilon = 0.1\!\sim\!0.2 \), entropy \( c_e=0.01\!\sim\!0.05 \)); or SAC with target entropy \( = -\text{action\_dim} \).
- Curiosity: start with RND (simple & strong); for control tasks try ICM on features from a small CNN/MLP; set \( \beta \) so intrinsic returns are \(10\%\!\sim\!50\%\) of extrinsic early on.
- Counts: for grid worlds or discrete obs, \( r^{\text{int}}=\beta/\sqrt{N(s)} \) is hard to beat.
- Diagnostics: plot state-visit heatmaps / pseudo-counts; KL to old policy (PPO); advantage stats; and the ratio of intrinsic/total reward over time.
Reward Shaping, Curriculum Learning & Domain Randomization
Goal: speed up learning without changing the optimal policy, and help the agent master tasks progressively while staying robust to environment variation.
1) Reward shaping (do it without changing the optimum)
Potential-based shaping adds a dense shaping term that preserves the optimal policy:
\[ r'(s,a,s') \;=\; r(s,a,s') \;+\; \gamma\,\Phi(s') \;-\; \Phi(s) \quad\Rightarrow\quad Q^{*\,'}(s,a) \;=\; Q^*(s,a) \;+\; \Phi(s). \]
- Intuition: \( \Phi(s) \) is like a potential; the shaped reward is the potential drop plus the original reward.
- Safe choices for \( \Phi \): negative distance-to-goal, negative time-to-go, learned value baseline \( \Phi(s)\!\approx\! \hat V(s) \).
- What to avoid: giving reward for actions that can be exploited (e.g., “spin = +1”). If you can’t write it as \( \gamma\Phi(s')-\Phi(s) \), the optimum may shift.
Practical recipe: start with sparse \( r \); add shaped term with weight \( \alpha \) and anneal: \[ r_t^{\text{train}} = r_t^{\text{sparse}} + \alpha_t\big(\gamma\Phi(s_{t+1})-\Phi(s_t)\big),\quad \alpha_t \downarrow 0. \]
2) Curriculum learning (make hard tasks learnable)
Let difficulty be a scalar \( d\in[0,1] \) (e.g., goal distance, obstacle density). Train on a moving distribution \( p_t(d) \) to keep the task just hard enough.
- Adaptive scheduler: keep success rate near target \( p^* \) by updating difficulty \[ d_{t+1} = \mathrm{clip}\!\left(d_t + \eta\,\big(p^* - \hat p_t\big),\,0,1\right), \] where \( \hat p_t \) is recent success rate.
- Bandit sampling: keep a few buckets of difficulty; sample the one whose success is closest to \( p^* \).
- Goal-conditioned RL + HER: relabel failures with achieved goals; this creates a natural curriculum in sparse-reward settings.
Tip: start with reset states “near the goal,” then widen the initialization region as competence grows.
3) Domain randomization (generalization & sim-to-real)
Maximize return under environment parameters \( \xi \) (e.g., mass, friction):
\[ \max_{\pi}\; \mathbb{E}_{\xi\sim p_t(\xi)}\Big[\sum_{k=0}^\infty \gamma^k\, r^\xi(s_k,a_k)\Big]. \]
- Randomize dynamics (masses, delays), sensors (noise, bias), visuals (lighting), and initial states.
- ADR (automatic domain randomization): expand parameter ranges where success is high; shrink where it is zero: \[ \textstyle \mathrm{range}_{t+1}(\xi)=\mathrm{range}_{t}(\xi)\times\big(1+\alpha\,( \hat p_t - p_\text{low})\big). \]
- Robust objective: try worst-case sampling for a fraction of updates: \[ \max_\pi \min_{\xi\in\mathcal S}\; \mathbb{E}\big[\textstyle\sum \gamma^t r^\xi\big] \quad\text{over a small adversarial set } \mathcal S. \]
Always log “train vs. held-out” parameter returns to detect overfitting to the randomized ranges.
4) Putting it together (minimal playbook)
- Start: sparse reward + potential shaping (small \( \alpha \)), easy curriculum \( d\!\approx\!0.2 \), moderate randomization.
- Mid-training: anneal \( \alpha\!\downarrow\!0 \); adapt \( d \) to keep success \( \approx p^*\in[0.6,0.8] \); widen randomization ranges.
- Late stage: mostly true reward (no shaping), near-final difficulties, held-out randomizations; evaluate robustly.
Plot three curves: (i) success vs. difficulty, (ii) return under train vs. held-out randomizations, (iii) proportion of shaped vs. true reward over time.
Exploration Cookbook (Defaults & Pitfalls)
| Method | Use when… | Key idea | Starter settings | Watch-outs |
|---|---|---|---|---|
| ε-greedy tabular/DQN | Discrete actions; simple baselines | Random action with prob. ε, else greedy | ε: 0.3 → 0.05 (linear over 0.5–1.0M steps) | Anneal too fast → premature exploitation |
| Softmax / Boltzmann tabular | Prefer smoother than ε-greedy | \(\pi(a\!\mid\!s) \propto e^{Q/\tau}\) | τ: 1.0 → 0.1; decay when returns stabilise | High τ = dithering; low τ = greedy collapse |
| UCB bandits | No states; pick informative arms | Optimism bonus shrinks with visits | c: 1–2; ensure accurate counts | Non-stationary rewards need resets/discount |
| Optimistic Q0 tabular | Sparse reward; need early trials | Seed high initial values | Q0 near max achievable return | Can slow convergence if set too high |
| Entropy bonus PPO | Policy gradients (discrete/cont.) | Add \(-c_e \mathcal H(\pi)\) to loss | ce: 0.01–0.05; decay over time | Too large → thrashy policy, poor returns |
| SAC temperature SAC | Continuous control; stability | Max entropy objective with learned α | Target entropy \(\approx -\)action_dim | Clamp α, monitor log-std floors |
| NoisyNets / Param noise DQN/PG | State-dependent, coherent exploration | Inject noise in weights, not actions | σ0: 0.4 (NoisyNets); anneal slowly | Too much noise → destabilised value targets |
| Bootstrapped DQN DQN | Deep discrete tasks; uncertainty approx. | Multiple heads ≈ Thompson sampling | Heads: 5–10; mask p≈0.8; shared body | Heavier memory/compute; track head usage |
| Count bonus grid/discrete | Small state spaces | Bonus \( \beta/\sqrt{N(s)} \) | β: 0.1–1.0; clip bonus to sane range | Explodes with huge state spaces |
| Pseudo-counts large obs | Images/large spaces | Density model → \(\hat N(x)\) → bonus | β tuned so int. return ≈ 10–30% early | Drift if density model overfits buffer |
| ICM curiosity image/control | Sparse reward; controllable dynamics | Forward-error bonus in feature space | η small (e.g., 1e-3); normalise/clip bonus | “Stuck but curious” loops; add extrinsic gates |
| RND hard games | Exploration in deceptive/sparse tasks | Predict fixed random target; error = bonus | η small; large/refreshing replay; layer norm | Predictor overfitting → bonus vanishes |
| HER goal-cond. | Goal spaces; sparse success | Relabel failed goals as targets | Relabel ratio: 4:1; mix future/episode goals | Use with off-policy (DDPG/TD3/SAC) |
| Safe exploration (Lagrangian) robotics | Costs (collisions/limits) must be bounded | Penalty \( -\lambda c_t \), learn \(\lambda\) | ηλ small (1e-3–1e-2); clip \(\lambda\ge0\) | Check true constraint satisfaction at eval |
Quick recipe: start with PPO + entropy (discrete or continuous). For continuous control, try SAC with learned temperature. In sparse tasks, add RND (games) or ICM (robotics) and keep intrinsic returns ≲ 10–50% of total early on; decay as extrinsic reward appears.
Model-Based RL & World Models
Idea: learn a model of the environment and use it to plan or to imagine extra data. Done well, this can slash sample complexity and unlock sim-to-real transfer.
1) Learn the dynamics (and reward) model
Supervised training from a replay buffer \( \mathcal D=\{(s_t,a_t,s_{t+1},r_t)\} \):
\[ \mathcal L_{\text{dyn}}(\theta)\;=\;-\!\!\sum_{(s,a,s')\in\mathcal D}\log p_\theta(s'\mid s,a) \quad\text{or}\quad \sum\big\|s' - f_\theta(s,a)\big\|_2^2, \]
\[ \mathcal L_{\text{rew}}(\xi)\;=\;-\!\!\sum\log p_\xi(r\mid s,a,s') \;\;\;(\text{or MSE}). \]
- Ensembles (5–7 heads) give epistemic uncertainty & reduce overfitting.
- Latent models learn \(z=g_\phi(s)\) and predict in latent space for stability.
- Train metric: report one-step NLL/MSE and multi-step roll-forward error.
2) Planning: shooting & MPC
Given horizon \(H\) and learned model \(\hat f,\hat r\), optimize an action sequence \(\mathbf a_{t:t+H-1}\):
\[ J_H(\mathbf a)=\sum_{k=0}^{H-1}\gamma^k\,\hat r(\hat s_{t+k},a_{t+k}) \;+\;\gamma^H \hat V(\hat s_{t+H}), \quad\hat s_{t+k+1}=\hat f(\hat s_{t+k},a_{t+k}). \]
- CEM/MPPI: sample many sequences, keep the elites, refit a Gaussian; repeat.
- MPC: execute only the first action, then re-plan at the next step.
- Value tail: bootstrap with \( \hat V \) to keep \(H\) short (robust to model error).
In real robots, \(H\in[5,20]\) with receding-horizon MPC is a solid default.
3) Model value expansion & Dyna
Value expansion (MVE) uses short imagined rollouts to improve value estimates:
\[ \hat V_{\text{MVE}}(s_t)= \mathbb E\!\left[\sum_{k=0}^{K-1}\gamma^k\,\hat r_k + \gamma^K V_\psi(\hat s_{t+K})\right], \quad \hat s\ \text{from the model}. \]
Dyna augments the replay buffer with model rollouts (short \(K\)) to train the policy/value more often per real step.
- MBPO-style: keep \(K\) very small (1–5) and refresh imagined data frequently.
- Stop-grad trick: treat model states as constants when updating the critic/actor.
4) Latent World Models (Dreamer-style)
Learn a stochastic latent dynamics \(p_\theta(z_{t+1}\!\mid z_t,a_t)\), an encoder \(q_\phi(z_t\!\mid s_{\le t},a_{
\[
\mathcal L_{\text{wm}} =
\sum_t\Big(
\mathbb E_{q_\phi}\big[-\log p_\xi(s_t\mid z_t)\big]
+ \beta\,\mathrm{KL}\!\big(q_\phi(z_t\mid \cdot)\,\|\,p_\theta(z_t\mid z_{t-1},a_{t-1})\big)
\Big).
\] Actor-critic learns entirely in imagination:
\[
z_{t+1}\!\sim p_\theta(z_{t+1}\mid z_t,a_t),\quad
a_t\!\sim \pi_\eta(a_t\mid z_t),\quad
J(\eta)=\mathbb E\!\left[\sum_{k=0}^{H-1}\gamma^k r_\xi(z_{t+k},a_{t+k})+\gamma^H V_\psi(z_{t+H})\right].
\] Use \(\lambda\)-returns for stable value targets:
\(G_t^\lambda=(1-\lambda)\sum_{n\ge1}\lambda^{n-1}G_t^{(n)}\),
with \(G_t^{(n)}=\sum_{k=0}^{n-1}\gamma^k r_{t+k}+\gamma^n V_\psi(\cdot)\).
5) Handle model uncertainty
Use an ensemble \(\{f^{(i)}\}\). Penalize plans where the ensemble disagrees:
\[ \sigma_{\text{dyn}}(s,a)=\mathrm{Std}_i\!\big(f^{(i)}(s,a)\big),\qquad \tilde r=\hat r - \beta\,\|\sigma_{\text{dyn}}\|. \]
- Conservative MB RL (MOPO/MOReL): subtract uncertainty from rewards or constrain to in-distribution regions.
- Offline MB RL: keep a trust region to behavior \(\pi_\beta\) via a KL constraint \( \mathrm{KL}(\pi(\cdot\mid s)\,\|\,\pi_\beta(\cdot\mid s))\le \epsilon\).
- Short horizons: prefer small \(H\) with a value tail when models are imperfect.
6) Practical playbook & diagnostics
- Seed: collect random data; fit a 5-head ensemble for \(\hat f,\hat r\).
- Choose path: (A) MPC with CEM; (B) MBPO/Dyna (short \(K\)); or (C) Dreamer for pixels.
- Keep training: add on-policy real rollouts each iteration; refit the model frequently.
- Rollout length sweep: test \(K\in\{1,3,5,10\}\); pick the best validation return.
- Logs to watch: (i) one- vs multi-step model error, (ii) plan value vs realized return, (iii) ensemble disagreement along chosen plans, (iv) fraction of imagined vs real updates.
- When to go model-free: if model loss falls yet return stalls, shorten \(H\) or switch to pure PPO/SAC.
MPC with CEM (Pseudo-code)
# Inputs: learned model \hat f, reward \hat r, value \hat V
# Horizon H, population size N, elite size M, iterations L
# Initial search distribution N(\mu, \Sigma)
for t = 0,1,2,...
# Receding-horizon loop
for l in 1..L:
# 1) Sample N action sequences from N(\mu, \Sigma)
A = { a^i_{t:t+H-1} ~ N(\mu, \Sigma) }_{i=1..N}
# 2) Evaluate each sequence with the model (with value tail)
for i in 1..N:
s = s_t
R = 0
for k in 0..H-1:
R += \gamma^k * \hat r(s, a^i_{t+k})
s = \hat f(s, a^i_{t+k})
R += \gamma^H * \hat V(s) # bootstrap tail
score[i] = R
# 3) Keep elites and refit Gaussian
E = top_M_by(score, A)
mu = mean(E) # per-time-step mean over sequences
Sig = cov(E) + \epsilon I # small diag jitter
# Execute only the first action of mu (MPC)
env.step(mu[0])
# Shift distribution forward; warm-start next iteration
Use short horizons (e.g., \(H\in[5,20]\)) and re-plan each step. On real robots: cap per-step wall-clock; if CEM can’t converge in time, fall back to the best-so-far sequence.
Weighted CEM update (optional): with normalized returns \(\tilde R_i\) and temperature \(\eta\)
\[ w_i=\frac{\exp(\eta\,\tilde R_i)}{\sum_j \exp(\eta\,\tilde R_j)},\quad \mu'=\sum_i w_i\,a^{(i)},\quad \Sigma'=\sum_i w_i\,(a^{(i)}-\mu')(a^{(i)}-\mu')^\top. \]
- Elites: \(M\approx 10\%{-}20\%\) of \(N\).\
- Action smoothing: parameterize sequences by lower-dimensional control points + cubic spline.
- Safety: penalize model-disagreement along the rollout: \( \tilde r=\hat r - \beta\,\|\sigma_{\text{ensemble}}\| \).
- Hybrid tail: learn \(\hat V\) with TD updates from real/imagined data.
Choosing a Model-Based Method
| Method | Best for | Pros | Watch-outs | Starter settings |
|---|---|---|---|---|
| MPC + CEM | Real-time control with low-dim obs; hardware in loop; short-horizon tasks. | Strong online performance; robust via re-planning; no policy net required; easy safety constraints. | Needs fast model inference; model bias hurts at long horizons; tune \(N,M,H,L\). | \(H=5\!-\!20\), \(N=256\!-\!1024\), elites \(10\%{-}20\%\); 3–5 inner iters; value tail \(\hat V\); ensemble penalty. |
| MBPO / Dyna | Continuous control (MuJoCo-like) with moderate obs; on-policy improv. from little real data. | Very sample-efficient; simple to implement; works with SAC/PPO; short model rollouts. | Too-long imagined rollouts drift off-manifold; need frequent model refresh. | Imagined rollout length \(K=1\!-\!5\); refresh imagined buffer every 250–1000 env steps; critic stop-grad. |
| Dreamer (World Models) | Pixel-based control; partial observability; learn in imagination efficiently. | End-to-end on images; actor-critic trains in latent space; great wall-clock returns on pixels. | Larger implementation; ELBO tuning; monitor latent posterior collapse and long-horizon compounding error. | RSSM latent; \(\lambda\)-returns; imagination horizon \(H=5\!-\!15\); entropy regularization; KL with free-bits. |
Tuning Checklist (Quick Wins & Fixes)
Notation: horizons \(H\), population \(N\), elites \(M\), rollout length \(K\), entropy temperature \(\alpha\), discount \(\gamma\), GAE \(\lambda\).
MPC + CEM online planning
- Start here: \(H=10\!-\!15\), \(N=512\), elites \(M=64\) (12.5%), inner iters \(L=3\).
- Next sweeps: try \(H\in\{5,10,15,20\}\); \(N\in\{256,512,1024\}\); add value tail \(\hat V\).
- Stability: add elite covariance jitter \(+\epsilon I\); smooth actions via spline control points.
- Safety: ensemble penalty \(\tilde r=\hat r - \beta\|\sigma_{\text{ens}}\|\) with \(\beta\) grid \(\{0,0.1,0.3\}\).
| Symptom | Likely cause | Fix |
|---|---|---|
| Good plan value, poor real return | Model bias at long \(H\) | Shorten \(H\); add \(\hat V\) tail; increase ensemble penalty |
| No improvement, plans similar | Low exploration in CEM | Raise \(N\)/\(M\); add weighted elites; increase init \(\Sigma\) |
| Jittery control | High var across time-steps | Spline parameterization; action smoothing; penalize accel/jerk |
| Over time limit | Planning too slow | Reduce \(N\)/\(L\); smaller nets; early-stop and execute best-so-far |
MBPO / Dyna short imagined rollouts
- Start here: \(K=1\!-\!5\) imagined steps; refresh model every \(500\) env steps; 5-head ensemble.
- Next sweeps: \(K\in\{1,3,5,10\}\); imagined:real ratio \(\in\{1:1,5:1,10:1\}\).
- Critic: stop-grad through model states; target smoothing; reward normalisation.
- Actor base: SAC with learned \(\alpha\) (target entropy \(\approx -|\mathcal A|\)).
| Symptom | Likely cause | Fix |
|---|---|---|
| Return drops as \(K\) ↑ | Compounding model error | Reduce \(K\); increase refresh; mix more real data |
| Critic loss explodes | Noisy targets from model | Clip rewards; lower \(\gamma,\lambda\); stronger target smoothing |
| Stalls after early gains | Model overfit to buffer | Shuffle/expand dataset; early-stop; stronger ensembles |
| Too random actions | \(\alpha\) too high (SAC) | Clamp / lower target entropy; monitor policy std floors |
Dreamer (World Models) pixels/latent
- Start here: RSSM latent; imagination \(H=5\!-\!15\); \(\lambda\)-returns (\(\lambda=0.95\)); entropy bonus on policy.
- Next sweeps: KL weight \(\beta\in\{0.5,1.0,2.0\}\); free-bits \(\in\{1,3,5\}\) nats; image augmentation on/off.
- Decoder: monitor recon NLL; avoid posterior collapse (use KL balancing or free-bits).
- Value/actor: normalise advantages; grad-clip \(0.5\!-\!1.0\).
| Symptom | Likely cause | Fix |
|---|---|---|
| Good recon, poor control | Latent not task-relevant | Add reward-predictor loss; action-cond. features; increase imagination updates |
| KL → 0 (collapse) | Too low KL pressure | Increase \(\beta\) or free-bits; KL balancing (prior vs posterior) |
| Unstable values | Long imagination, high variance | Shorten \(H\); higher \(\lambda\); advantage normalisation |
| No real transfer | Overfit to visuals | Domain randomize visuals; stronger augmentations; regularise decoder |
General tips: run \(3\!-\!5\) seeds; track CI bands; sweep the fewest knobs first (one per method); log model error vs. return to decide when to shorten horizons or fall back to model-free updates.
What to Log (Dashboard Preset)
Group metrics by category so issues jump out at a glance. Below are practical keys that work for PPO, SAC, and Model-Based methods.
Core & Episode
episode/return_mean,episode/return_median,episode/return_stdepisode/len_mean,episode/success_rate(if defined)time/steps,time/fps,time/wall_clock,seed
Rewards (decomposed)
reward/ext_mean,reward/int_mean,reward/total_meanreward/intrinsic_share= int / (ext+int)
PPO / Actor–Critic
ppo/policy_loss,ppo/value_loss,ppo/entropyppo/kl_mean,ppo/clip_fraction,ppo/approx_kladv/mean,adv/std,td/delta_mean,explained_varianceoptim/lr_policy,optim/lr_value,optim/grad_norm
SAC (continuous)
sac/actor_loss,sac/critic1_loss,sac/critic2_loss,sac/alphasac/policy_entropy,sac/policy_std_meanreplay/size,replay/age_mean,replay/prio_mean(if PER)
Model-Based (MPC / MBPO / Dreamer)
model/one_step_loss,model/k_step_loss,model/reward_lossmodel/ensemble_disagreement,model/refresh_intervalmbpo/imagined_real_ratio,mbpo/rollout_Kmpc/H,mpc/N,mpc/elites_M,mpc/iters_L,mpc/plan_value,mpc/realized_returndreamer/kl,dreamer/free_bits,dreamer/imagination_H
Safety & Numerics
cost/return,cost/rate,lagrange/lambda(if constrained)optim/nan_count,optim/grad_clip,norm/obs_mean,norm/obs_std
Weights & Biases (Python dict)
log = {
# core
"episode/return_mean": ret_mean, "episode/return_median": ret_med,
"episode/return_std": ret_std, "episode/len_mean": len_mean,
"episode/success_rate": succ, "time/steps": steps, "time/fps": fps,
# reward breakdown
"reward/ext_mean": r_ext, "reward/int_mean": r_int,
"reward/total_mean": r_ext + r_int,
"reward/intrinsic_share": (r_int / max(1e-8, r_ext + r_int)),
# PPO
"ppo/policy_loss": pol_loss, "ppo/value_loss": val_loss,
"ppo/entropy": ent, "ppo/kl_mean": kl, "ppo/clip_fraction": clip_frac,
"adv/mean": adv_mean, "adv/std": adv_std, "td/delta_mean": delta_mean,
"explained_variance": ev, "optim/lr_policy": lr_pi, "optim/lr_value": lr_v,
"optim/grad_norm": grad_norm,
# SAC
"sac/actor_loss": act_loss, "sac/critic1_loss": q1_loss,
"sac/critic2_loss": q2_loss, "sac/alpha": alpha,
"sac/policy_entropy": pol_ent, "sac/policy_std_mean": std_mean,
"replay/size": replay_size, "replay/age_mean": age_mean,
# Model-based
"model/one_step_loss": m1, "model/k_step_loss": mk,
"model/reward_loss": mr, "model/ensemble_disagreement": ens_dis,
"mbpo/imagined_real_ratio": ratio, "mbpo/rollout_K": K,
"mpc/H": H, "mpc/N": N, "mpc/elites_M": M, "mpc/iters_L": L,
"mpc/plan_value": plan_v, "mpc/realized_return": real_ret,
# Safety & numerics
"cost/return": cost_ret, "cost/rate": cost_rate, "lagrange/lambda": lam,
"optim/nan_count": nan_count
}
wandb.log(log, step=steps)TensorBoard (PyTorch SummaryWriter)
from torch.utils.tensorboard import SummaryWriter
w = SummaryWriter(log_dir)
w.add_scalar("episode/return_mean", ret_mean, steps)
w.add_scalar("ppo/entropy", ent, steps)
w.add_scalar("ppo/kl_mean", kl, steps)
w.add_scalar("sac/alpha", alpha, steps)
w.add_scalar("model/one_step_loss", m1, steps)
w.add_scalar("mpc/plan_value", plan_v, steps)
# ...repeat for the keys you useMLflow (single call)
import mlflow
mlflow.log_metrics({
"episode/return_mean": ret_mean,
"ppo/entropy": ent, "ppo/kl_mean": kl,
"sac/alpha": alpha, "model/one_step_loss": m1
}, step=steps)Practical tips: (1) log per-update and per-episode summaries; (2) keep tag names stable so you can overlay runs; (3) record config (γ, λ, ε, clip, α, horizons) once at run start for reproducibility.
Recommended Dashboards (Layouts & Panels)
Mirror these panel orders in Weights & Biases or TensorBoard. Group runs by experiment and color by seed; aggregate with median + 95% CI where available.
PPO / Actor–Critic Layout discrete or continuous
- Smoothing: 0.9–0.95; show unsmoothed as thin line for sanity.
- Alerts: KL spike > 2× median; entropy < small threshold early; clip fraction near 0 or 1 for several epochs.
SAC Layout continuous control
- Target entropy: ≈ −|A|; α should adapt smoothly—if it collapses quickly, increase target entropy slightly.
- Alerts: critic loss spikes, α > 1 for long, policy std hitting floor early.
Model-Based Layout MPC / MBPO / Dreamer
- Compare: plan value should loosely track realized return; widening gap ⇒ shorten horizon, add value tail, or increase uncertainty penalty.
- Alerts: model error ↓ but return flat; disagreement ↑ along chosen plans; Dreamer KL → 0 (posterior collapse).
Dashboard Presets & Notes
- Aggregation: show per-seed thin lines + group median with 95% CI band.
- X-axis: environment steps; secondary axis for wall-clock if comparing methods.
- Smoothing: 0.9–0.95 for noisy curves; keep raw overlay.
- Panels you can small-multiple: per-env returns (if multiple tasks), per-action std (continuous), per-head Q (Bootstrapped DQN).
- Colors: consistent per-method across pages; seeds as shade variants.
Diagnostics & Debugging
These checks catch most RL training pathologies early. Symbols: policy \( \pi_\theta \), old policy \( \pi_{\text{old}} \), value \( V_\phi \), advantage \( A_t \), TD-error \( \delta_t \), entropy \( \mathcal H \), KL \( D_{\mathrm{KL}} \).
1) Training health signals
- Entropy: \( \mathcal H(\pi_\theta(\cdot|s_t)) \) should decrease gradually. A flatline at 0 ⇒ premature collapse; flat high ⇒ no learning.
- KL to old policy: \( D_{\mathrm{KL}}\!\big(\pi_{\text{old}}\;\|\;\pi_\theta\big) \). For PPO, keep small & steady; spikes ⇒ too-large steps or clip too loose.
- Explained variance: \( \mathrm{EV}=1-\frac{\mathrm{Var}(R_t - V_\phi)}{\mathrm{Var}(R_t)} \). Rising toward \(1\) is good; negative ⇒ value targets inconsistent.
- Advantage stats: mean \(\approx 0\), monitor std/percentiles of \( A_t \). Exploding std ⇒ normalize or reduce \( \lambda,\gamma \) horizon.
2) Reward accounting
Plot per-step and cumulative extrinsic vs intrinsic rewards.
- Decompose: \( r_t = r_t^{\text{ext}} + \beta\, r_t^{\text{int}} \).
- Share over a window \(W\): \[ \rho_{\text{int}}=\frac{\sum_{t\in W}\beta\,r_t^{\text{int}}}{\sum_{t\in W} \big( r_t^{\text{ext}}+\beta\,r_t^{\text{int}}\big)}. \] Target early exploration \( \rho_{\text{int}}\approx 0.1\!\sim\!0.5 \), then taper.
- Check reward scale: value targets / critic loss should not dwarf the policy loss.
Sanity probe: replace env with a trivial “go right” or “constant reward” stub; verify monotonic learning in minutes.
3) Advantage & returns (GAE/TD)
- TD-error: \( \delta_t = r_t + \gamma V_\phi(s_{t+1}) - V_\phi(s_t) \).
- GAE advantages: \[ A_t=\sum_{l=0}^{T-t-1}(\gamma\lambda)^l\,\delta_{t+l}. \] Plot histogram/quantiles of \( \delta_t \) and \( A_t \); heavy tails ⇒ clip/normalize or reduce horizon.
- Bootstrap correctness: if episode terminates, drop bootstrap term or set \( \gamma=0 \) at terminal.
4) Algorithm-specific sentinels
PPO. Track clipping fraction \[ f_{\text{clip}}=\frac{1}{N}\sum_t \mathbf{1}\Big(\big|r_t-1\big|>\epsilon\Big),\quad r_t=\frac{\pi_\theta(a_t|s_t)}{\pi_{\text{old}}(a_t|s_t)}. \] Healthy runs: \( f_{\text{clip}}\approx 0.1\!\sim\!0.3 \). Near 0 ⇒ too timid; near 1 ⇒ over-stepping.
SAC. Monitor temperature \( \alpha \) and entropy target: \( \mathcal H_{\text{target}}\!\approx -|\mathcal A| \) (continuous). If \( \alpha \!\to\! 0 \) too fast ⇒ policy freezes; if \( \alpha \) explodes ⇒ noisy actions, no improvement.
DQN/TD3. Q-values should bracket returns; large positive bias ⇒ overestimation (add double-Q or stronger target noise).
5) Behavior & exploration probes
- State-visit heatmaps: coverage should expand then concentrate around competent trajectories.
- Action usage: for discrete, plot softmax probs; for continuous, per-dim mean/std. Collapse to corners ⇒ saturation / low entropy.
- Curiosity burn-in: ratio \( \rho_{\text{int}} \) should decline as extrinsic reward becomes learnable.
- Stuck detector: no change in return + high entropy ⇒ reward shaping or exploration insufficient; low entropy ⇒ premature exploitation.
6) Data & replay sanity
- On-policy freshness: for PPO/ A2C, ensure trajectories used once; detect leakage by tagging rollout IDs.
- Replay skew: for SAC/TD3/DQN, track age histogram of sampled transitions; extreme staleness ⇒ increase refresh or use prioritized replay.
- Normalization drift: log running stats (obs/return mean–std). Sudden jumps ⇒ reset stats or clip observations.
| Symptom | Likely cause | Quick fix |
|---|---|---|
| Return flat, entropy ↓ fast | Over-regularized / too large LR | Lower LR; raise entropy bonus or SAC target |
| Value loss ↑, EV ↓ | Value targets noisy / reward scale off | Normalize returns; reduce \( \gamma \)/\( \lambda \); clip rewards |
| KL spikes / NaNs | Exploding grads / bad init | Grad-clip; smaller batch step; orthogonal init |
7) Optimizer & gradients
- Log per-update grad-norm \( \|\nabla_\theta \mathcal L\|_2 \) and apply clipping (e.g., 0.5–1.0).
- Check learning-rate warm-up / cosine decay. Too aggressive decay ⇒ stalled learning.
- Weight stats: running mean/var of last linear layers; saturation ⇒ lower init scale or add LayerNorm.
Numerics: enable torch.autocast cautiously; if using FP16, keep critics in FP32; add small \( \epsilon \) in log-prob / variance terms.
8) Reproducibility & ablations
- Fix seeds for
env,numpy,torch; set deterministic cuDNN when needed. - Run ≥ 3–5 seeds; report mean ± 95% CI. Plot per-seed curves to spot outliers.
- Ablate one knob at a time ( \( \gamma, \lambda, \alpha, c_{\text{ent}}, \epsilon_{\text{clip}} \) ).
Minimal plot checklist (add to your dashboard)
- \( G \) (episode return) mean/median with CI; success rate (if applicable).
- Entropy \( \mathcal H \), KL \( D_{\mathrm{KL}} \) (PPO), temperature \( \alpha \) (SAC), clipping fraction \( f_{\text{clip}} \) (PPO).
- Value loss, explained variance, advantage std & histogram.
- Intrinsic vs extrinsic reward stacks and \( \rho_{\text{int}} \) over time.
- State-visit heatmap / coverage metric; action distribution drift.
- Replay age histogram (off-policy), grad-norm, learning rate.
Practical Applications and Examples
Game Playing (e.g., AlphaGo, Atari Games):
Reinforcement learning has made headlines by enabling agents to achieve superhuman performance in complex games. For instance, AlphaGo, developed by DeepMind, learned to play the board game Go at a masterful level by playing against itself millions of times. Similarly, RL agents have conquered a range of Atari games, learning strategies directly from pixel inputs without any manual feature engineering.
Robotics (e.g., Autonomous Navigation, Robotic Arm Manipulation):
In robotics, RL helps robots learn to perform tasks through trial and error. A robot may start by randomly moving its arm to pick up objects, receiving rewards for successful grasps. Over time, it refines its actions to reliably manipulate objects without human intervention. RL also aids in autonomous navigation, where drones or ground vehicles learn to avoid obstacles, follow paths, and adapt to changing conditions in real-time.
Benefits and Challenges
Benefits:
- Adaptability: RL agents learn continuously, improving their strategies as they gain more experience.
- Flexibility: Applicable to a wide variety of tasks where explicit instructions or labels are hard to specify, including control problems, game environments, and dynamic scenarios.
Challenges:
- Data Efficiency: RL often requires large amounts of interaction data, which can be time-consuming and costly to gather, especially in real-world settings.
- Stability and Convergence: Achieving stable learning results can be tricky, and poor hyperparameter tuning can slow progress or lead to erratic policies.
- Safety and Ethics: In scenarios like autonomous driving, the agent must learn without causing harm. Ensuring safety and compliance with ethical guidelines is an active area of research.
Advancing the Field
As the field progresses, researchers are exploring ways to make RL more sample-efficient, more interpretable, and better aligned with human values. Techniques like hierarchical reinforcement learning (breaking down tasks into smaller sub-problems), transfer learning (reusing knowledge from previous tasks), and offline RL (learning from previously collected datasets without further environment interaction) are pushing the boundaries of what RL agents can achieve.Why Study Reinforcement Learning
Understanding How Machines Learn Through Interaction
Exploring Core Concepts in Decision-Making and Control
Building Intelligent Systems for Real-World Applications
Connecting Theory with Experimentation and Simulation
Preparing for Advanced Study and Emerging Careers in AI
Key Terms (Reinforcement Learning)
A quick glossary of RL concepts. Inline math uses KaTeX (kept short to avoid layout issues).
- Markov Decision Process (MDP)
- Formal RL setting defined by \( \langle \mathcal{S}, \mathcal{A}, P, r, \gamma \rangle \): states, actions, dynamics \(P\), reward \(r\), discount \( \gamma \).
- Agent / Environment
- The agent selects actions; the environment returns next state and reward.
- State \(s\) / Observation \(o\)
- State is the full situation; observation may be partial/noisy. Partial observability leads to POMDPs.
- Action \(a\)
- What the agent does. Can be discrete (e.g., left/right) or continuous (e.g., torques).
- Policy \( \pi_\theta(a\mid s) \)
- Mapping from states to action probabilities/parameters; \(\theta\) are learnable weights.
- Reward \(r_t\)
- Immediate scalar feedback from the environment after taking an action.
- Return \(G_t\)
- Discounted sum of future rewards: \( G_t=\sum_{k=0}^{\infty}\gamma^k r_{t+k+1} \).
- State-Value \( V^\pi(s) \)
- Expected return from state \(s\) following policy \(\pi\): \( V^\pi(s)=\mathbb{E}_\pi[G_t\mid s_t=s] \).
- Action-Value \( Q^\pi(s,a) \)
- Expected return from \( (s,a) \) then following \(\pi\): \( Q^\pi(s,a)=\mathbb{E}_\pi[G_t\mid s_t=s,a_t=a] \).
- Advantage \( A^\pi(s,a) \)
- How much better an action is than average at \(s\): \( A^\pi(s,a)=Q^\pi(s,a)-V^\pi(s) \).
- Bellman Equation
- Recursive definition of value; basis for dynamic programming and TD methods.
- TD Error \( \delta_t \)
- One-step value mismatch: \( \delta_t=r_t+\gamma V(s_{t+1})-V(s_t) \). Used for critic updates.
- GAE (Generalized Advantage Estimation)
- Low-variance advantage estimator: \( A_t=\sum_{l\ge0}(\gamma\lambda)^l\,\delta_{t+l} \). \(\lambda\in[0,1]\).
- Exploration vs Exploitation
- Trade-off between trying new actions and using known good ones (ε-greedy, entropy, curiosity, RND, etc.).
- Policy Entropy \( \mathcal H \)
- Randomness of the policy; encourages exploration. SAC targets \( \mathcal H_{\text{target}}\approx -|\mathcal A| \) (continuous).
- KL Divergence \( D_{\mathrm{KL}} \)
- Distance between policies (old vs new). PPO keeps KL small via clipping.
- PPO Clip \( \epsilon \ )
- Limits policy update size by clipping the likelihood ratio; typical \( \epsilon=0.1\!-\!0.2 \).
- SAC Temperature \( \alpha \)
- Weight on entropy term; learned to hit the target entropy (continuous control).
- Replay Buffer
- Memory of past transitions for off-policy learning (SAC/TD3/DQN). Enables sample reuse.
- Target Network
- Delayed/slow-moving copy of a value network to stabilise bootstrapping updates.
- On-Policy / Off-Policy
- On-policy methods use fresh data from the current policy (PPO); off-policy methods learn from replay data (SAC/TD3/DQN).
- Horizon \(H\)
- How many steps ahead you plan/optimise (e.g., MPC planning horizon, imagination length).
- Model-Free / Model-Based
- Model-free learns policy/values directly; model-based learns dynamics/reward to plan or imagine data.
- Reward Shaping
- Guidance added to rewards. Safe form: potential-based \( \gamma\Phi(s')-\Phi(s) \) (preserves optimal policy).
- Curriculum Learning
- Progressively increase task difficulty to match target success rates.
- Domain Randomization
- Randomise dynamics/observations/visuals during training for robustness and sim-to-real.
See also: Exploration & Intrinsic Motivation, Reward Shaping & Curriculum, Model-Based RL & World Models, Diagnostics & Debugging.
Reinforcement Learning: Quick FAQs
What’s the difference between value-based and policy-gradient methods?
Value-based learns \(Q(s,a)\) or \(V(s)\) and acts greedily (e.g., DQN). Policy-gradient directly optimises \( \pi_\theta(a\mid s) \) by ascending \( \nabla_\theta J(\theta) \) (e.g., PPO/SAC). Policy gradients handle continuous actions and stochastic policies more naturally.
When should I choose PPO vs. SAC?
- PPO: great default for discrete or continuous control; simple, robust.
- SAC: best for continuous control when you want stability + sample efficiency via entropy regularisation.
Rule of thumb: discrete → PPO; continuous with smooth control → SAC.
How do I set \( \gamma \) and \( \lambda \)?
Discount \( \gamma \in [0.95,0.99] \) (effective horizon \( \approx \tfrac{1}{1-\gamma} \)). Long-horizon tasks can use 0.995. GAE \( \lambda \in [0.9,0.97] \) (0.95 is a strong default): higher = smoother but more bias.
How much entropy should I use?
PPO: entropy bonus coefficient \( c_e \approx 0.01\!-\!0.05 \), decay over time.
SAC: set a target entropy; common default is \( \mathcal H_{\text{target}} \approx -|\mathcal A| \) for continuous actions. Let \( \alpha \) learn to meet that target.
Recommended PPO hyper-parameters?
- Clip \( \epsilon = 0.1\!-\!0.2 \), epochs 3–10, minibatch size 64–256.
- Advantage normalisation on; gradient clip 0.5–1.0; value loss coefficient 0.5–1.0.
- Learning rate \( 3\!\times\!10^{-4} \) (start), cosine/linear decay.
How do I shape rewards without breaking optimality?
Use potential-based shaping: add \( \gamma\Phi(s’)-\Phi(s) \). This preserves the optimal policy while providing dense guidance. Choose \( \Phi(s) \) like negative distance-to-goal or a learned value baseline.
Best exploration strategies for sparse rewards?
- RND (hard games), ICM (robotics/features), count/pseudo-count bonuses (discrete/grids).
- Goal-conditioned + HER for tasks with explicit goals.
- Keep intrinsic share \( \rho_{\text{int}} \) ≤ 10–50% early; evaluate with intrinsic off.
Training is unstable—what should I check first?
- Normalise advantages/returns; verify \( A_t \) mean ≈ 0.
- Reduce learning rate; add grad-clip; check reward scale.
- For PPO: monitor KL spikes and clip fraction (aim 0.1–0.3).
- For SAC: watch \( \alpha \) and policy std floors.
On-policy vs. off-policy—what’s the practical difference?
On-policy (PPO/A2C) uses fresh data; stable but less sample-efficient. Off-policy (SAC/TD3/DQN) reuses replay data; more sample-efficient but needs careful replay/target stability.
How do I handle partial observability?
- Frame-stacking or history windows.
- Recurrent policies (LSTM/GRU) or latent state-space models (RSSM; Dreamer-style).
- Belief state filters if you know observation noise models.
Any quick tips for sim-to-real transfer?
- Domain randomisation (masses, friction, delays, sensor noise, lighting).
- Short planning horizons or value tails to limit model bias.
- Safety constraints (cost penalties/Lagrangian, action clipping, velocity/jerk limits).
Reinforcement Learning: Conclusion
Reinforcement Learning (RL) is a powerful framework for decision-making and control: agents learn by interacting with an environment, receiving feedback, and iteratively improving their behaviour. Beyond benchmark games, modern RL underpins safe autonomy in robotics, adaptive control in industry, and closed-loop optimisation across networked systems.
- It’s more than an algorithm: success depends on reward design, exploration, data pipelines, and robust evaluation.
- Choose the right tool: PPO/SAC are strong baselines; model-based RL (MPC/MBPO/Dreamer) trades complexity for sample efficiency.
- Learn safely & generalise: shape rewards without changing optima, use curricula, and apply domain randomisation/constraints.
- Measure what matters: track returns, entropy/KL (PPO), temperature (SAC), model error vs. realised returns, and reproducible CIs.
As compute, simulators, and sensors improve, RL will continue to shape intelligent systems that can learn, adapt, and thrive in complex, changing environments.
Next steps: review Diagnostics & Debugging, browse the Quick FAQs, or explore applied work in Robotics & Autonomous Systems and the broader AI & ML hub.
Reinforced Learning: Review Questions and Answers:
1. What is Reinforcement Learning?
Answer: Reinforcement learning is a branch of machine learning in which an agent learns to make decisions by interacting with an environment. It receives feedback in the form of rewards or penalties that guide its behavior over time. This trial-and-error approach helps the agent improve its performance based on accumulated experiences. The methodology is widely used for tasks that involve sequential decision-making and dynamic environments.
2. How does the agent-environment interaction work in Reinforcement Learning?
Answer: In reinforcement learning, the interaction between the agent and the environment is a continuous cycle where the agent observes the current state, takes an action, and then receives a reward along with a new state. This cycle forms the basis for learning as the agent adjusts its strategy based on the feedback received. The environment’s response encapsulates both the immediate reward and the impact on future states. Over time, this iterative process enables the agent to develop an effective policy for decision-making.
3. What are the key components of a reinforcement learning system?
Answer: A reinforcement learning system typically includes an agent, an environment, a set of states, available actions, and a reward function. The agent follows a policy that maps states to actions, while the environment provides feedback through rewards and state transitions. Value functions and models of state transitions often play an essential role in estimating long-term benefits. Together, these components enable the agent to learn and refine its behavior through iterative updates.
4. Explain the role of reward functions in reinforcement learning.
Answer: The reward function serves as the primary feedback mechanism in reinforcement learning by quantifying the immediate benefit of an action taken by the agent. It signals the desirability of the outcomes, guiding the agent toward behaviors that maximize cumulative rewards. A well-designed reward function is critical because it aligns the agent’s actions with the overall objectives of the task. This function thereby influences the learning process and ultimately determines the success of the agent’s policy.
5. What is the difference between value-based and policy-based methods in reinforcement learning?
Answer: Value-based methods concentrate on estimating the value of states or state-action pairs and then deriving a policy from these value estimates. In contrast, policy-based methods directly optimize the policy without relying on an intermediate value function. Value-based approaches, such as Q-learning, use iterative updates to improve value estimates, whereas policy-based techniques, like policy gradients, adjust the policy parameters directly based on performance. Each approach offers distinct advantages depending on the complexity and nature of the problem being addressed.
6. How do exploration and exploitation trade-offs affect reinforcement learning?
Answer: The exploration-exploitation trade-off is fundamental in reinforcement learning as it forces the agent to balance between trying new actions (exploration) and leveraging known rewarding actions (exploitation). This balance is crucial because excessive exploration can slow down the learning process, while too much exploitation might prevent the discovery of more effective strategies. Managing this trade-off ensures that the agent gathers sufficient information about its environment while still optimizing for rewards. Consequently, this dynamic directly influences the efficiency and convergence of the learning algorithm.
7. Describe the concept of Q-learning in reinforcement learning.
Answer: Q-learning is a widely used value-based reinforcement learning algorithm that focuses on estimating the optimal action-value function for state-action pairs. It operates by iteratively updating Q-values using the Bellman equation, which connects current rewards with the estimated future rewards. This update process is independent of the policy being followed, allowing the agent to learn the optimal policy over time. Due to its simplicity and effectiveness, Q-learning has become a cornerstone technique in reinforcement learning applications.
8. How can reinforcement learning be applied in real-world scenarios?
Answer: Reinforcement learning finds application in numerous real-world scenarios such as robotics, autonomous vehicles, finance, and game playing. It empowers systems to adapt to changing environments by learning from continuous interactions and optimizing decision-making processes. In robotics, for instance, reinforcement learning can enable machines to navigate complex terrains and perform intricate tasks. Its adaptability and scalability make it a valuable tool for solving practical problems that require dynamic and sequential decision-making.
9. What are some challenges associated with reinforcement learning algorithms?
Answer: Reinforcement learning algorithms often encounter challenges including high sample complexity, where an enormous number of interactions is needed to learn effective policies. They may also face issues with stability and convergence, especially in environments with sparse or delayed rewards. Balancing exploration and exploitation can further complicate the learning process, potentially leading to suboptimal performance. Additionally, scaling these algorithms to handle high-dimensional or continuous action spaces remains an active area of research with significant practical challenges.
10. How does reinforcement learning contribute to advancements in AI and decision-making?
Answer: Reinforcement learning contributes to AI by providing a framework where systems can learn optimal behaviors through direct interaction with their environments. This approach has led to breakthroughs in complex tasks, such as mastering strategic games and optimizing industrial processes. It also enables the development of autonomous systems that can adapt to real-time changes and make informed decisions without human intervention. Overall, reinforcement learning plays a pivotal role in pushing the boundaries of intelligent automation and adaptive decision-making.
Reinforced Learning: Thought-Provoking Questions and Answers
1. How can reinforcement learning be integrated with other AI paradigms to solve complex real-world problems?
Answer: Reinforcement learning can be effectively combined with deep learning to form deep reinforcement learning, enabling agents to process high-dimensional inputs such as images or sensor data. This integration allows for the automatic extraction of features from raw data, which in turn facilitates more sophisticated decision-making in complex environments. By leveraging the strengths of both paradigms, systems can learn intricate policies that adapt to dynamic conditions and unforeseen scenarios. The synergy between these techniques expands the applicability of reinforcement learning across various real-world domains.
Integrating reinforcement learning with other approaches, such as supervised and unsupervised learning, further enhances its capability to model complex problems. Such hybrid systems can use labeled data to guide learning while still benefiting from the autonomous exploration intrinsic to reinforcement learning. This cross-disciplinary approach improves generalization, reduces training time, and creates more resilient AI systems capable of handling multifaceted challenges.
2. In what ways could advancements in reinforcement learning revolutionize personalized learning experiences?
Answer: Advancements in reinforcement learning could lead to highly adaptive educational platforms that tailor content to individual learners based on their progress and interaction patterns. By continuously analyzing performance data, these systems can adjust difficulty levels, recommend specific learning resources, and provide real-time feedback that aligns with each student’s unique needs. This adaptive approach ensures that learners are neither overwhelmed nor under-challenged, thereby optimizing the educational experience. As a result, reinforcement learning could transform traditional classroom settings into dynamic, personalized learning environments.
Furthermore, the integration of reinforcement learning in educational technologies can facilitate intelligent tutoring systems that evolve over time. These systems can simulate various teaching strategies and adjust methodologies based on student responses, leading to a more engaging and effective learning process. The resulting personalized educational experience not only enhances comprehension but also fosters a deeper engagement with the subject matter.
3. What ethical considerations emerge from deploying reinforcement learning in autonomous decision-making systems?
Answer: Deploying reinforcement learning in autonomous systems raises critical ethical issues such as accountability, transparency, and fairness. When decisions made by these systems have significant impacts on human lives, it is essential to ensure that the decision-making processes are explainable and free from bias. The potential for unintended negative consequences, such as discrimination or violation of privacy, demands rigorous oversight and ethical guidelines. These considerations highlight the need for a responsible approach to the development and deployment of reinforcement learning technologies.
In addition, establishing clear regulatory frameworks is vital to manage the ethical implications of autonomous systems powered by reinforcement learning. Collaborative efforts among technologists, policymakers, and ethicists are required to develop standards that ensure the technology is used for the greater good. This multidisciplinary engagement can help balance innovation with the protection of individual rights and societal values.
4. How might the scalability challenges of reinforcement learning be addressed in large-scale, dynamic environments?
Answer: Addressing scalability challenges in reinforcement learning involves employing techniques such as hierarchical learning, distributed training, and transfer learning. Hierarchical learning decomposes complex tasks into simpler sub-tasks, which makes the overall problem more manageable and improves convergence rates. Distributed training leverages parallel computation, allowing multiple agents or simulations to run simultaneously and accelerate the learning process. Transfer learning further enhances scalability by utilizing previously acquired knowledge to reduce the need for extensive training in new, yet similar, environments.
Additionally, refining exploration strategies and adopting efficient algorithms like actor-critic methods can help manage the computational load. By optimizing these strategies, reinforcement learning systems can adapt to large state spaces and continuously evolving conditions without compromising performance. Ongoing research in scalable algorithms promises to further bridge the gap between theoretical models and practical, real-world applications.
5. Can reinforcement learning techniques be combined with unsupervised learning to enhance decision-making in uncertain scenarios?
Answer: Yes, reinforcement learning can be integrated with unsupervised learning techniques to improve decision-making under uncertainty. Unsupervised learning helps in identifying hidden patterns and structures within raw data, which can then inform the state representations used in reinforcement learning. This combination enables agents to better understand their environments even when explicit labels or rewards are sparse. By fusing the exploratory nature of reinforcement learning with the pattern recognition strengths of unsupervised methods, systems can achieve more robust and informed decision-making.
Such a hybrid approach not only accelerates the learning process but also enhances the overall quality of the learned policies. The improved state representations reduce noise and emphasize the most relevant features, leading to more accurate predictions and effective actions. Ultimately, this integration offers a powerful framework for tackling complex, uncertain environments in a variety of applications.
6. How does the concept of delayed rewards in reinforcement learning influence long-term strategic planning in AI systems?
Answer: The concept of delayed rewards compels reinforcement learning agents to evaluate the long-term consequences of their actions rather than focusing solely on immediate gains. This encourages the development of strategies that yield benefits over an extended period, which is essential for tasks involving complex, sequential decision-making. By accounting for delayed rewards, agents learn to prioritize actions that may initially seem suboptimal but lead to superior cumulative outcomes. This foresight is a critical element in the formation of sustainable, long-term strategies in AI systems.
Moreover, managing delayed rewards requires sophisticated techniques such as temporal difference learning to assign proper credit to actions taken at earlier time steps. These methods enable the agent to balance immediate performance with future rewards, ensuring that short-term decisions contribute positively to long-term objectives. The focus on long-term gains ultimately results in more resilient and adaptable AI strategies capable of thriving in dynamic environments.
7. What role could reinforcement learning play in advancing human-AI collaboration in high-stakes environments?
Answer: Reinforcement learning can serve as a critical enabler for human-AI collaboration by providing real-time decision support in high-stakes environments such as healthcare, disaster management, and defense. By continuously learning from interactions and feedback, reinforcement learning systems can offer adaptive strategies that complement human expertise. These systems can analyze complex data streams, identify emerging patterns, and suggest optimal courses of action that might not be immediately apparent to human operators. The collaboration between humans and AI leads to more informed and effective decision-making in critical situations.
This cooperative dynamic also promotes transparency and mutual learning, where AI systems can explain their recommendations and adapt based on human feedback. As the technology matures, reinforcement learning is expected to play an increasingly central role in environments where rapid, high-stakes decisions are required. The result is a synergistic partnership that enhances overall performance and safety.
8. How might transfer learning and reinforcement learning work together to reduce training times in complex tasks?
Answer: Transfer learning can significantly reduce training times in reinforcement learning by providing a head start through pre-trained models or policies from related tasks. When an agent is initialized with knowledge acquired from a similar environment, it can bypass the initial phase of random exploration and focus on fine-tuning its strategy. This integration accelerates the convergence of the learning process by leveraging previously learned representations and decision patterns. The combined approach is particularly useful in complex tasks where starting from scratch would be computationally expensive and time-consuming.
Furthermore, the collaboration between transfer learning and reinforcement learning enables continuous improvement across diverse environments. As agents encounter new challenges, they can apply prior knowledge to adapt quickly, thereby enhancing overall efficiency. This synergy not only minimizes training durations but also contributes to the development of more versatile and scalable AI systems.
9. What potential impacts might reinforcement learning have on industries that require real-time adaptive strategies?
Answer: Reinforcement learning has the potential to transform industries that rely on real-time adaptive strategies by enabling systems to learn and react to dynamic conditions quickly. In sectors like finance, logistics, and energy management, the ability to adjust strategies based on immediate feedback can lead to optimized performance and resource utilization. Reinforcement learning algorithms continuously refine their policies, resulting in decision-making processes that are both flexible and resilient. This dynamic adaptation is crucial for maintaining a competitive edge in rapidly changing environments.
The real-time capabilities of reinforcement learning also facilitate improved process automation and risk management. By constantly learning from real-world interactions, AI systems can preemptively address challenges and optimize operational efficiency. As a result, industries that adopt these techniques may experience significant improvements in productivity and innovation.
10. How can simulation environments be improved to better train reinforcement learning agents for unpredictable real-world situations?
Answer: Simulation environments can be enhanced by incorporating greater levels of complexity, randomness, and realism to mimic the unpredictability of the real world. This involves designing simulations that expose agents to a wide range of scenarios, including rare or extreme events, to better prepare them for unexpected challenges. Enhanced physics models, realistic environmental dynamics, and diverse scenario generation can provide a more comprehensive training ground for reinforcement learning agents. Such improvements help bridge the gap between simulated and real-world conditions, leading to more robust policies.
In addition, techniques like domain randomization and procedural content generation can further diversify the training data. By varying the parameters and conditions within the simulation, agents learn to generalize their skills and adapt to new situations more effectively. The resulting enriched simulation environments play a critical role in developing AI systems that perform reliably under real-world uncertainties.
11. What are the future prospects of reinforcement learning in contributing to sustainable and efficient resource management?
Answer: Reinforcement learning holds great promise for sustainable and efficient resource management by optimizing processes such as energy distribution, water allocation, and waste management. These systems can analyze real-time data and predict future trends to make informed decisions that minimize waste and maximize efficiency. By dynamically adjusting strategies based on environmental feedback, reinforcement learning can significantly reduce resource consumption and operational costs. This proactive management aligns well with global sustainability goals and the pursuit of eco-friendly solutions.
Moreover, the integration of reinforcement learning into smart grid technologies and environmental monitoring systems can further enhance the management of natural resources. Adaptive algorithms can balance supply and demand more effectively, facilitate the incorporation of renewable energy sources, and promote overall system resilience. The resulting advancements are expected to drive innovations that support long-term environmental sustainability and efficient resource use.
12. How might the integration of reinforcement learning with emerging quantum computing technologies change the landscape of AI research?
Answer: The integration of reinforcement learning with quantum computing could revolutionize AI research by enabling the processing of extraordinarily complex data sets and state spaces that are currently intractable with classical methods. Quantum computing offers the potential for massive parallelism and speed-ups in computational tasks, which may drastically shorten training times for reinforcement learning algorithms. This convergence could lead to the development of novel quantum-enhanced models that learn more efficiently and tackle problems of unprecedented scale. The fusion of these technologies promises to unlock new paradigms in intelligent decision-making and optimization.
Additionally, quantum computing could facilitate innovative exploration strategies and more effective handling of uncertainty in reinforcement learning. By leveraging quantum principles, AI systems might develop entirely new frameworks for modeling dynamic environments and predicting long-term outcomes. This groundbreaking integration has the potential to reshape the future of AI, driving research and applications toward previously unimagined frontiers.
Numerical Problems and Solutions
1. Q-Learning Update Calculation
Solution:
Step 1: Calculate the target using the formula: target = reward + (gamma × max future Q) = 10 + (0.9 × 7) = 10 + 6.3 = 16.3.
Step 2: Determine the temporal difference (TD) error: TD error = target − current Q = 16.3 − 5 = 11.3.
Step 3: Update the Q-value: new Q = current Q + (alpha × TD error) = 5 + (0.1 × 11.3) = 5 + 1.13 = 6.13.
2. Discounted Reward Sum Calculation
Solution:
Step 1: Identify the rewards: 3, 5, and 2 for the three time steps.
Step 2: Apply the discount factor: second reward becomes 0.8 × 5 = 4 and third reward becomes (0.8)² × 2 = 0.64 × 2 = 1.28.
Step 3: Sum the discounted rewards: total reward = 3 + 4 + 1.28 = 8.28.
3. Expected Return for Two Actions
Solution:
Step 1: For Action A, compute the expected reward per step: 0.7 × 8 = 5.6.
Step 2: Calculate the two-step return for Action A: 5.6 + (0.95 × 5.6) = 5.6 + 5.32 = 10.92.
Step 3: For Action B, compute the expected reward per step: 0.5 × 12 = 6 and two-step return: 6 + (0.95 × 6) = 6 + 5.7 = 11.7; hence, Action B offers a higher expected return.
4. Expected Reward in an Epsilon-Greedy Strategy
Solution:
Step 1: Calculate the expected reward per action using the probabilities: (0.8 × 9) + (0.2 × 3) = 7.2 + 0.6 = 7.8.
Step 2: Multiply by the number of actions: 7.8 × 10 = 78.
Step 3: Conclude that the total expected reward over 10 actions is 78.
5. Epsilon Decay in Epsilon-Greedy Strategy
Solution:
Step 1: Start with an initial epsilon value of 1.
Step 2: Calculate the total decay over 5 episodes: 5 × 0.1 = 0.5.
Step 3: Determine the new epsilon: 1 − 0.5 = 0.5, representing a 50% reduction in exploration probability.
6. Bellman Update Calculation for State Value
Solution:
Step 1: Identify the immediate reward (4) and the estimated value of the next state (10).
Step 2: Multiply the next state value by the discount factor: 0.85 × 10 = 8.5.
Step 3: Sum the immediate reward with the discounted future value: 4 + 8.5 = 12.5.
7. Cumulative Discounted Reward Over 4 Time Steps
Solution:
Step 1: Recognize the rewards: 2, 4, 6, and 8, with a discount factor of 0.9.
Step 2: Compute each discounted reward: 2, 0.9 × 4 = 3.6, (0.9)² × 6 = 0.81 × 6 = 4.86, (0.9)³ × 8 = 0.729 × 8 = 5.832.
Step 3: Sum them up: 2 + 3.6 + 4.86 + 5.832 = 16.292.
8. Q-Learning Update with Different Parameters
Solution:
Step 1: Compute the target: reward + (gamma × max future Q) = 5 + (0.95 × 10) = 5 + 9.5 = 14.5.
Step 2: Calculate the TD error: 14.5 − 7 = 7.5.
Step 3: Update the Q-value: 7 + (0.2 × 7.5) = 7 + 1.5 = 8.5.
9. Reward-to-Go Calculation Using Discount Factor
Solution:
Step 1: Identify the rewards from the trajectory: [3, 6, 9] with a discount factor of 0.8.
Step 2: For the second time step, compute the reward-to-go: 6 + (0.8 × 9) = 6 + 7.2 = 13.2.
Step 3: Conclude that the reward-to-go for the second time step is 13.2.
10. Expected Reward in a Probabilistic Grid Navigation
Solution:
Step 1: Calculate the reward for a correct move: 0.3 × 5 = 1.5.
Step 2: Calculate the reward for a random move: 0.7 × (–1) = –0.7.
Step 3: Sum the values: 1.5 − 0.7 = 0.8 as the expected reward for one move.
11. Multi-Armed Bandit Total and Average Reward Calculation
Solution:
Step 1: Identify the average rewards of the three arms: 4, 7, and 10.
Step 2: Compute the total reward by pulling each arm 5 times: 5 × (4 + 7 + 10) = 5 × 21 = 105.
Step 3: Determine the average reward per pull: 105 ÷ 15 = 7.
12. Discounted Cumulative Reward and Relative Weight Calculation
Solution:
Step 1: Calculate the discounted rewards for a series of 5 actions with rewards [1, 2, 3, 4, 5] and a discount factor of 0.9: 1 + (0.9 × 2) + (0.9)² × 3 + (0.9)³ × 4 + (0.9)⁴ × 5. Using powers: (0.9)² = 0.81, (0.9)³ = 0.729, (0.9)⁴ = 0.6561; thus, the sum is 1 + 1.8 + 2.43 + 2.916 + 3.2805 = 11.4265.
Step 2: Identify the effective weight of the first reward as 1 (undiscounted) and the last reward as 0.9⁴ = 0.6561.
Step 3: Determine the contribution: the first reward contributes 1 × 1 = 1, while the last contributes 5 × 0.6561 = 3.2805; hence, the last reward contributes approximately 3.28 times as much in the cumulative calculation compared to the first reward’s base value.